Research & Writing
89 data essays, notebooks, and case studies. Each one takes a public dataset apart and shows the gears: the markets, the models, the climate, and the people the numbers describe.
Cross-Asset Correlation
When correlations go to 1, your diversification was a fair-weather friend
The Dollar's Gravity
The dollar's gravity: which currencies track it, and which float free
The Dow's Fat Tails
The Dow's worst month was a 5-sigma event a bell curve says is impossible
The 2021 Inflation Surge
The 2021 inflation surge was the broadest in decades, not the worst
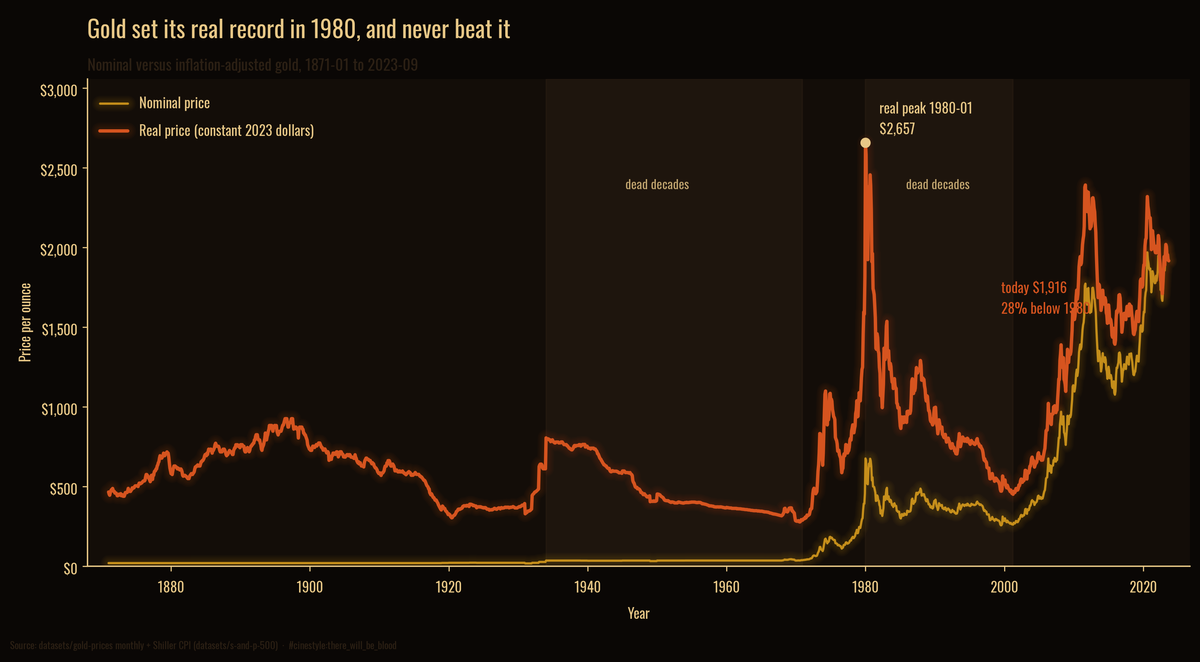
Gold in Real Terms
Gold made its real high in 1980, and has been losing the rematch ever since
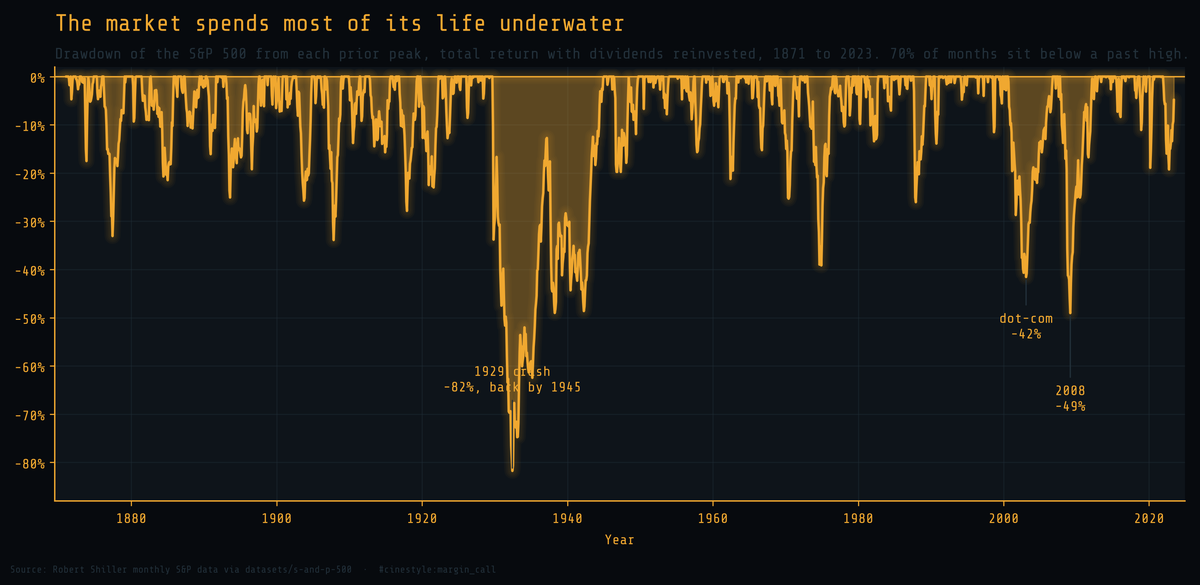
150 Years of Drawdowns
150 years of S&P 500 drawdowns: the market is usually underwater
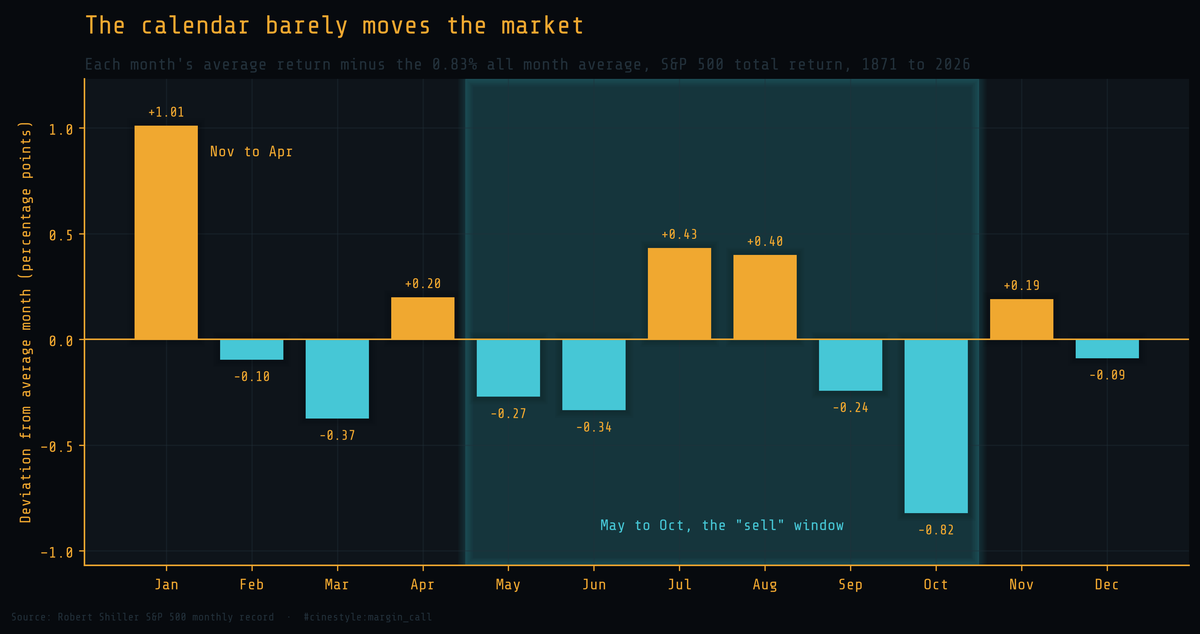
Market Seasonality
Sell in May, and other things the calendar does not actually tell you
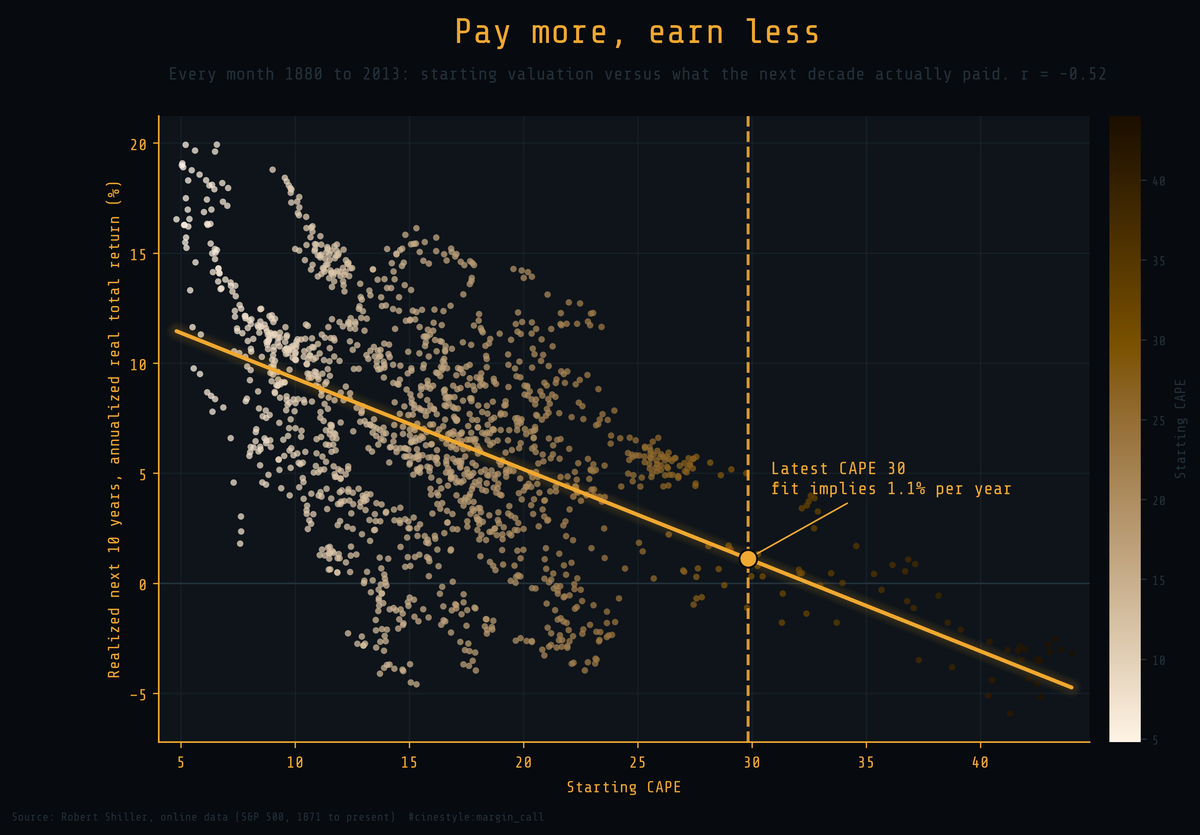
Valuation and Returns
What you pay for stocks sets what you earn, and right now you are paying a lot
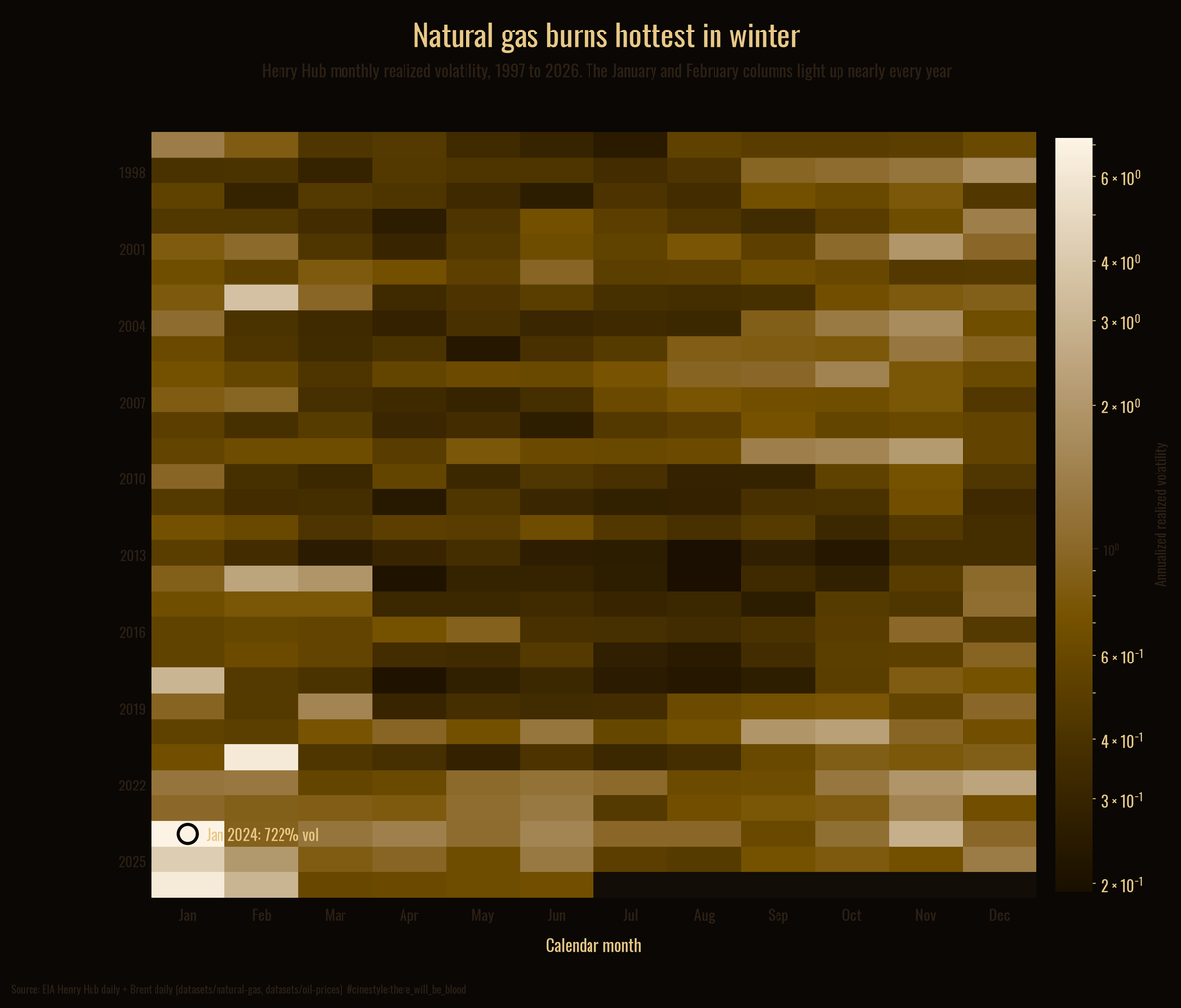
The Widow-Maker
Natural gas is the widow-maker, and the winter is where it earns the name
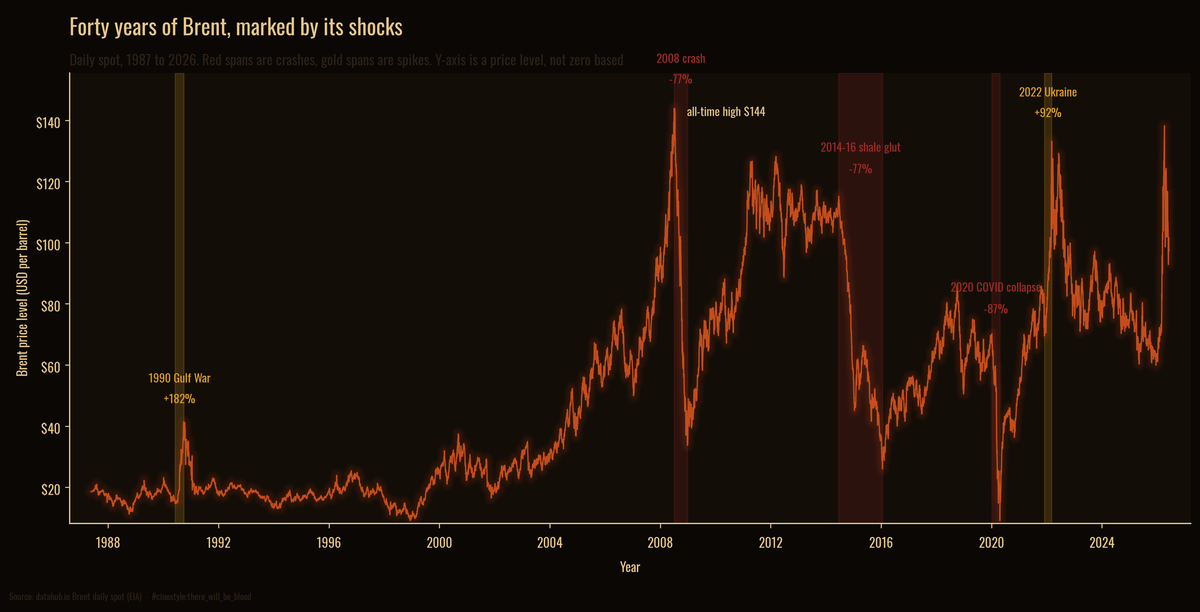
Forty Years of Oil Shocks
Forty years of Brent, and the shocks that define it
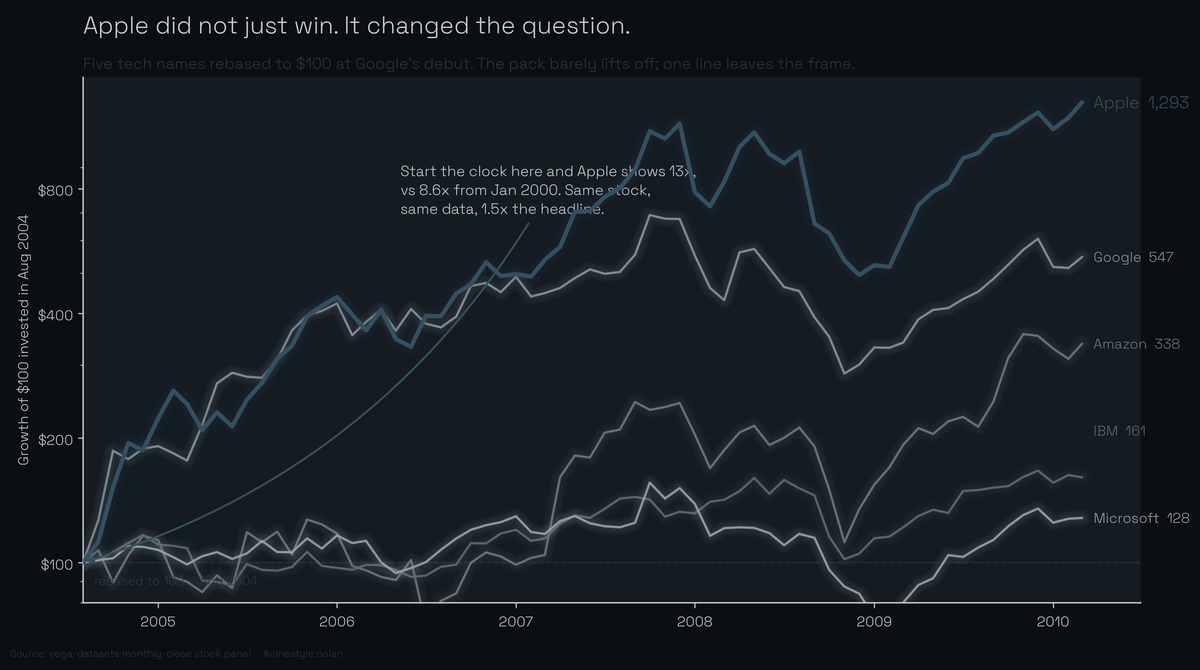
Apple Versus the Field
Apple turned $1 into $8.60. Everyone else mostly stood still.
On disabling ML in production
What I learned when my live trading system's ML ensemble silently degraded in production, and the disciplined reintroduction of machine learning that came after.
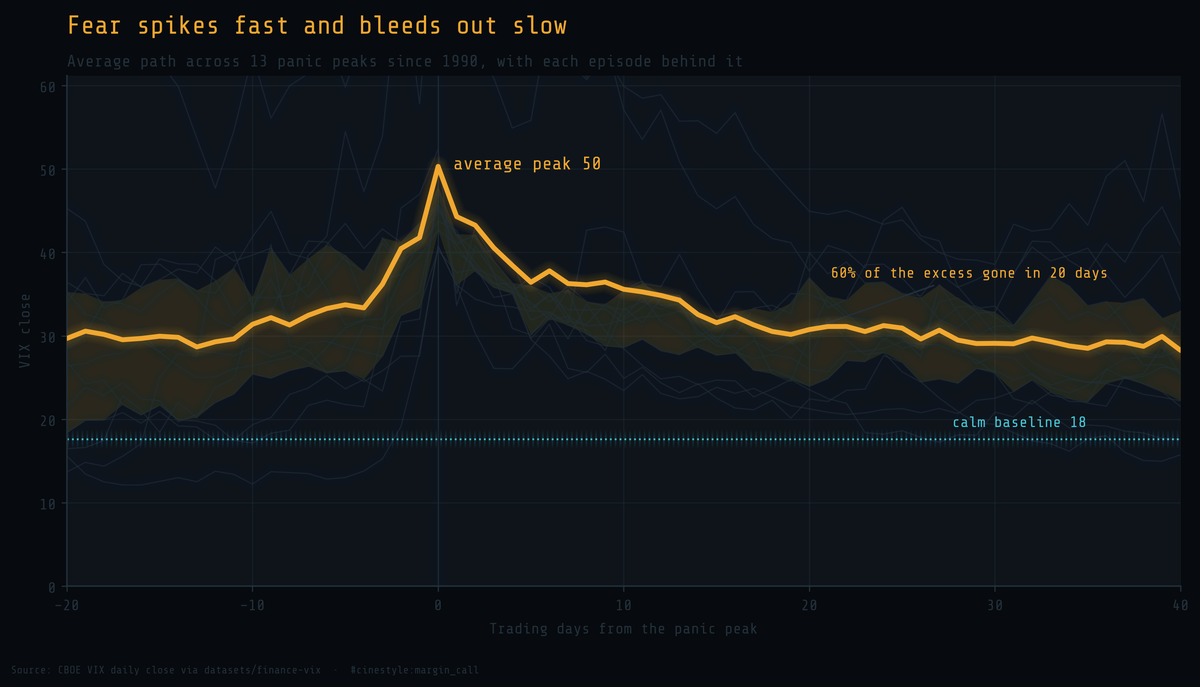
Anatomy of the VIX
The VIX spends most of its life bored, then loses its mind
Atlas in production: putting a forecasting system in front of real capital
How the Atlas forecasting system handles 542,000 rows/second of market data with sub-second regime detection — async service architecture, dependency-ordered startup, and 10Hz health monitoring.
How Atlas's database got 810× faster: a single-pattern fix
Atlas couldn't start. The trading system's database initialization was taking 6.6 seconds, blocking 37 features from loading. The fix was small.

Brain Signal Redundancy
62 signals, 21 real dimensions: redundancy that does not look like redundancy
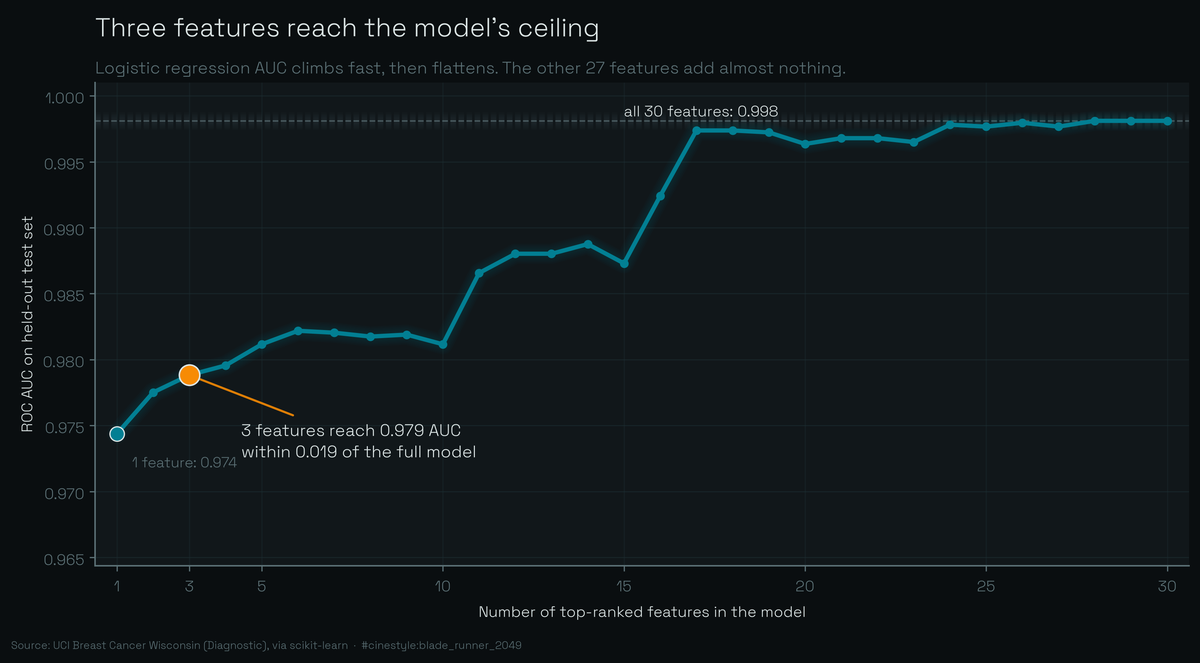
Diagnosing on Three Features
Three of thirty features get you within 0.02 AUC of the full model
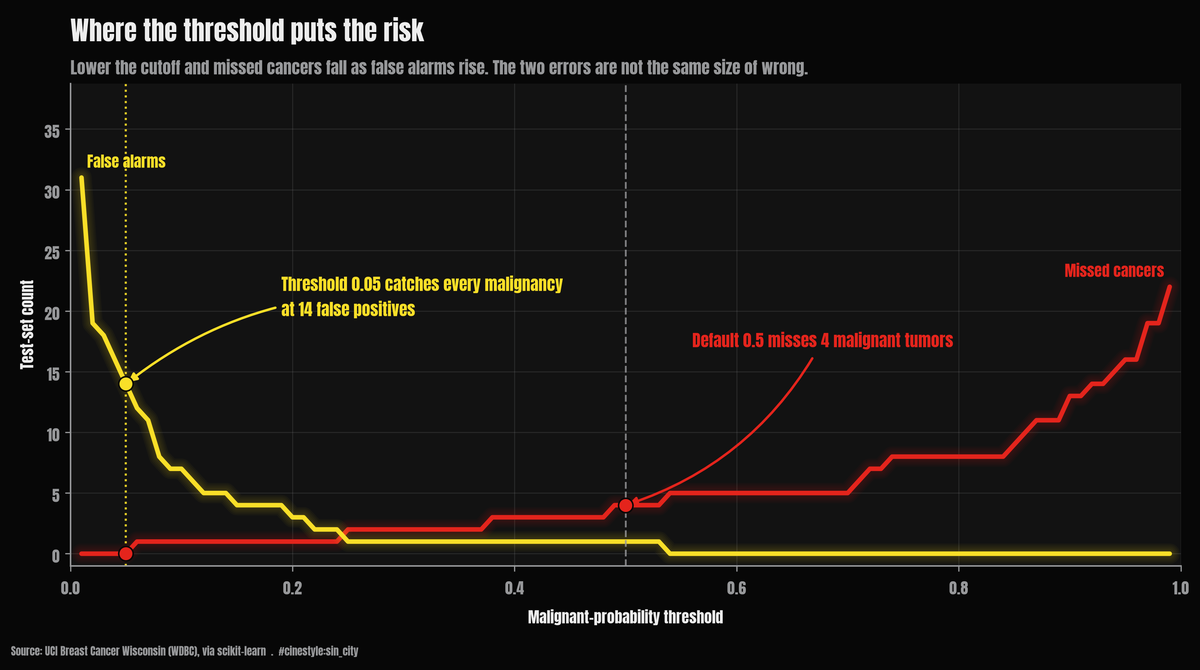
The Cancer Decision Threshold
I would rather flag thirteen benign tumors than miss four malignant ones
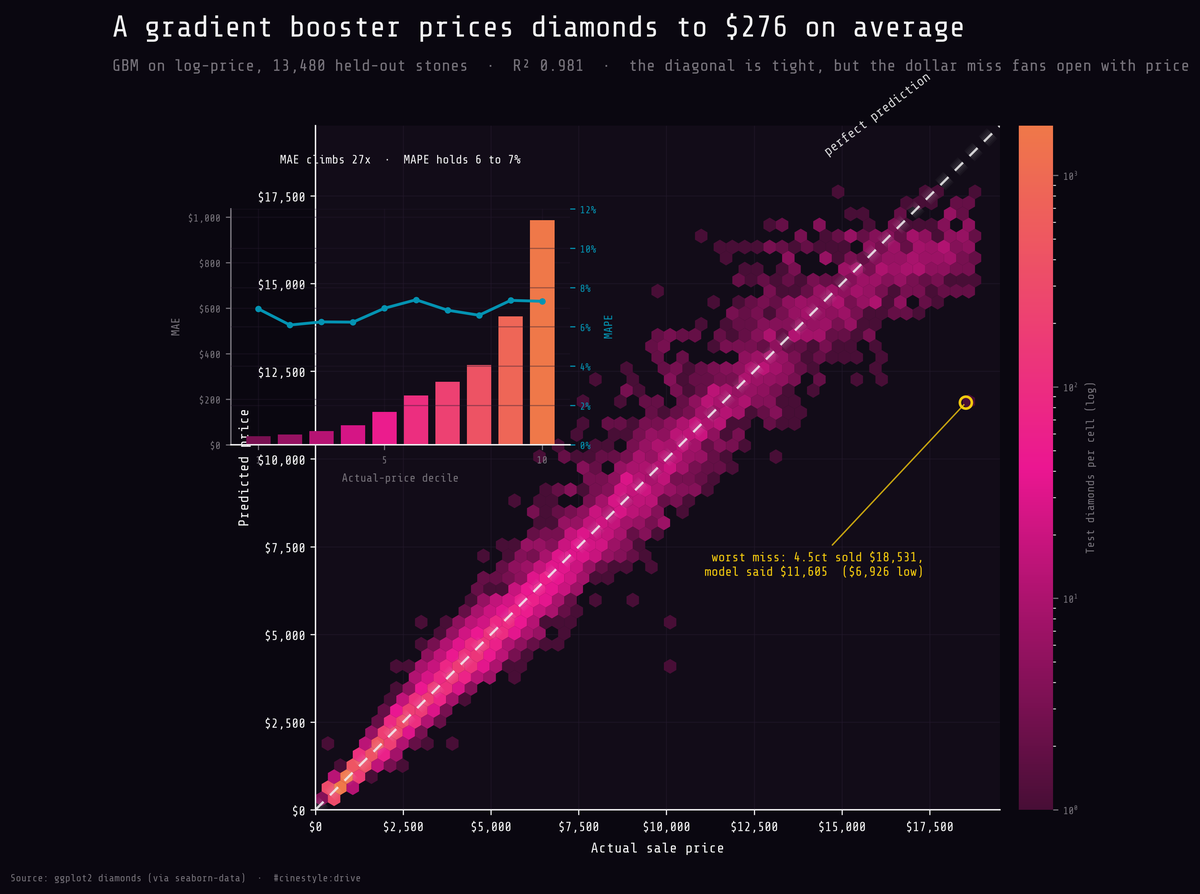
Pricing Diamonds
A gradient booster prices diamonds to $276. Then it meets a big one.
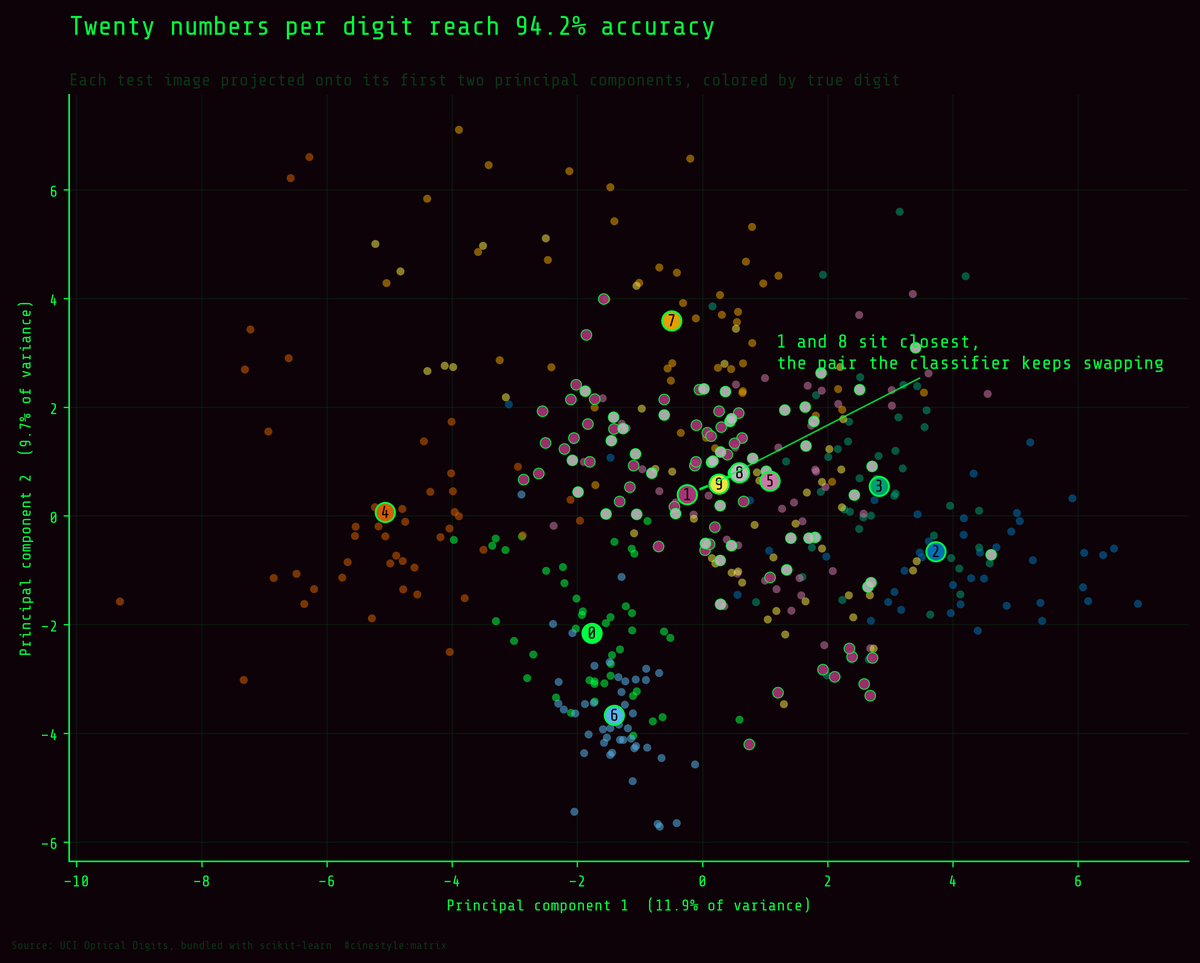
Recognizing Digits
Twenty numbers per digit gets you 94% of the way there
The Pixels That Matter
Twelve of the 64 pixels are dead, and the classifier never misses them
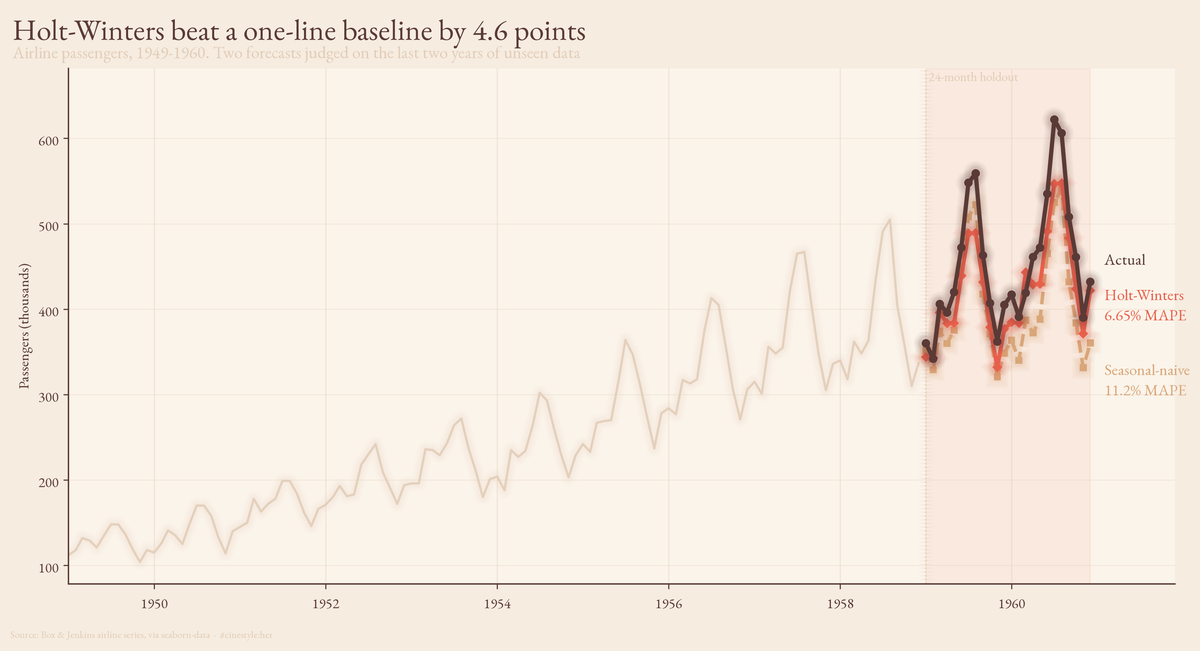
Forecasting Air Travel
Losing to Holt-Winters by 4.6 points was the good news
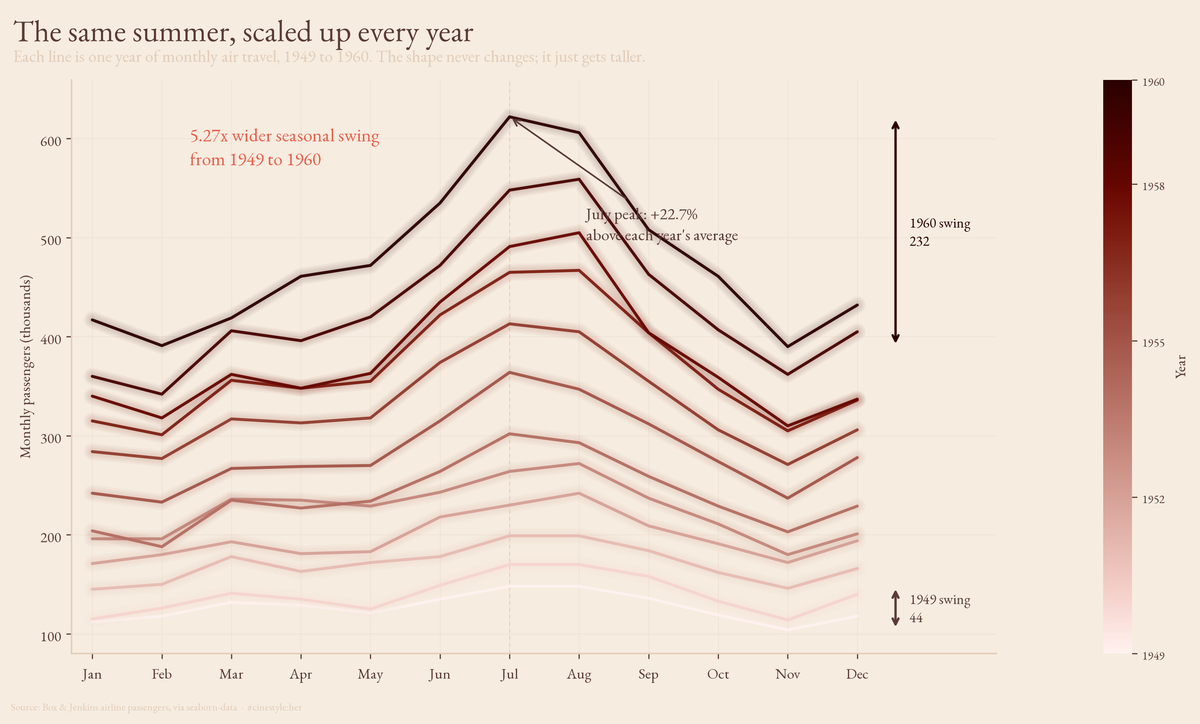
Decomposing Air Travel
44 passengers in 1949, 232 in 1960, the same summer bump
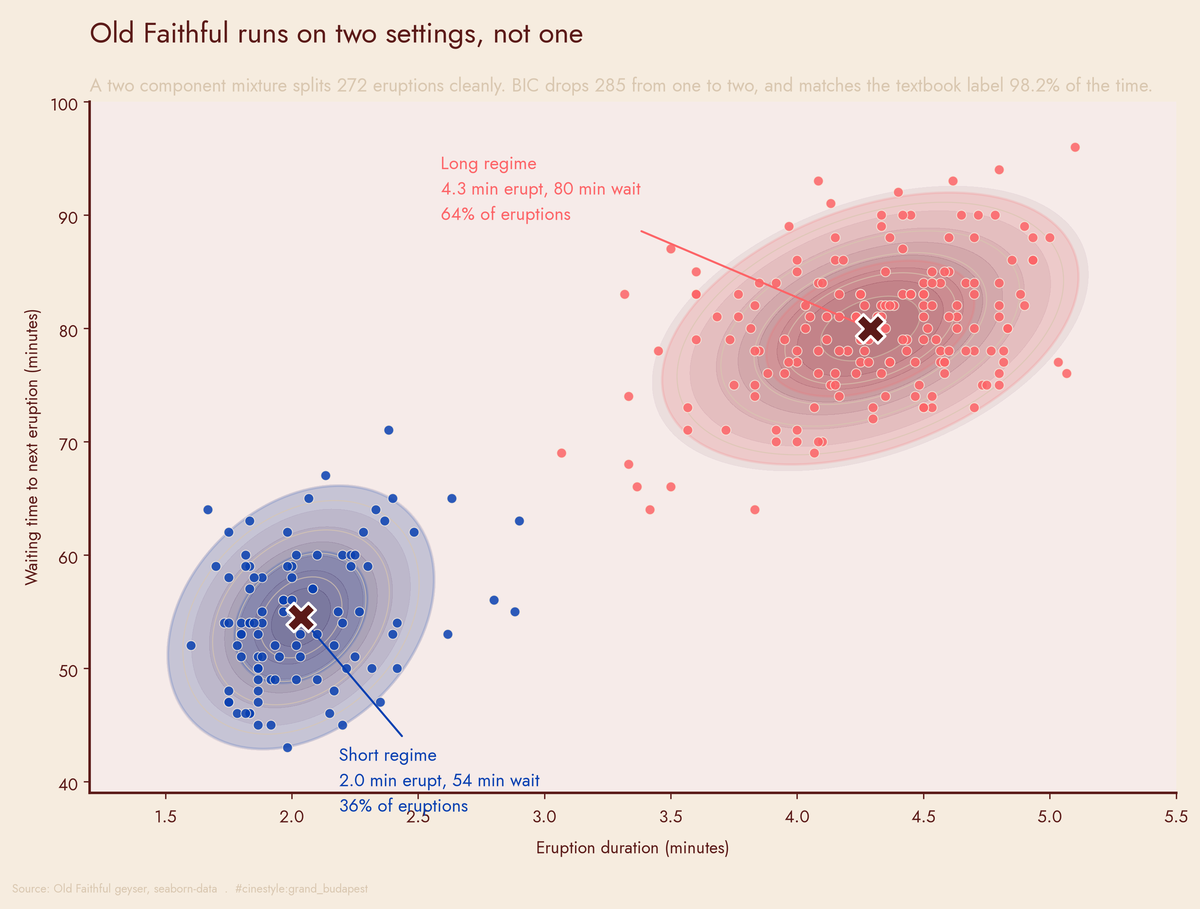
Old Faithful's Two Modes
Old Faithful is two geysers wearing a trench coat
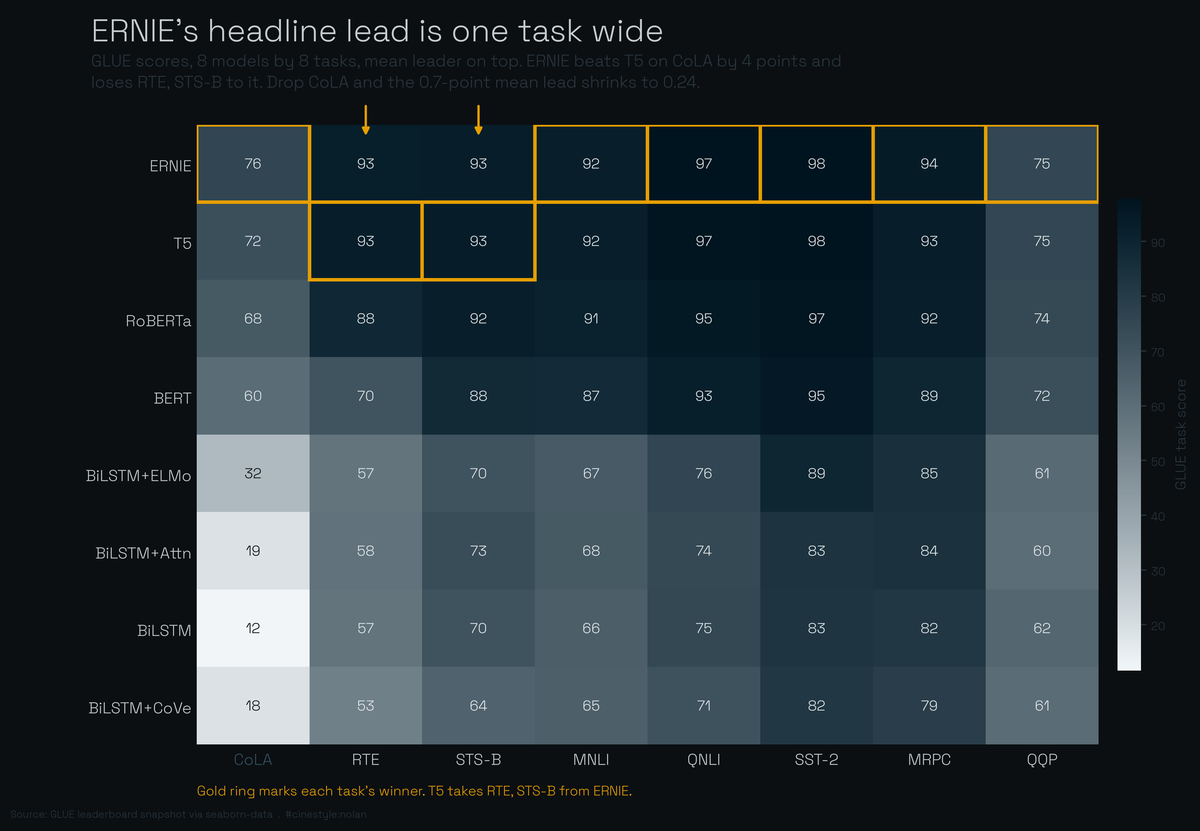
The GLUE Leaderboard
The 0.7 points that decide a leaderboard, and where they come from
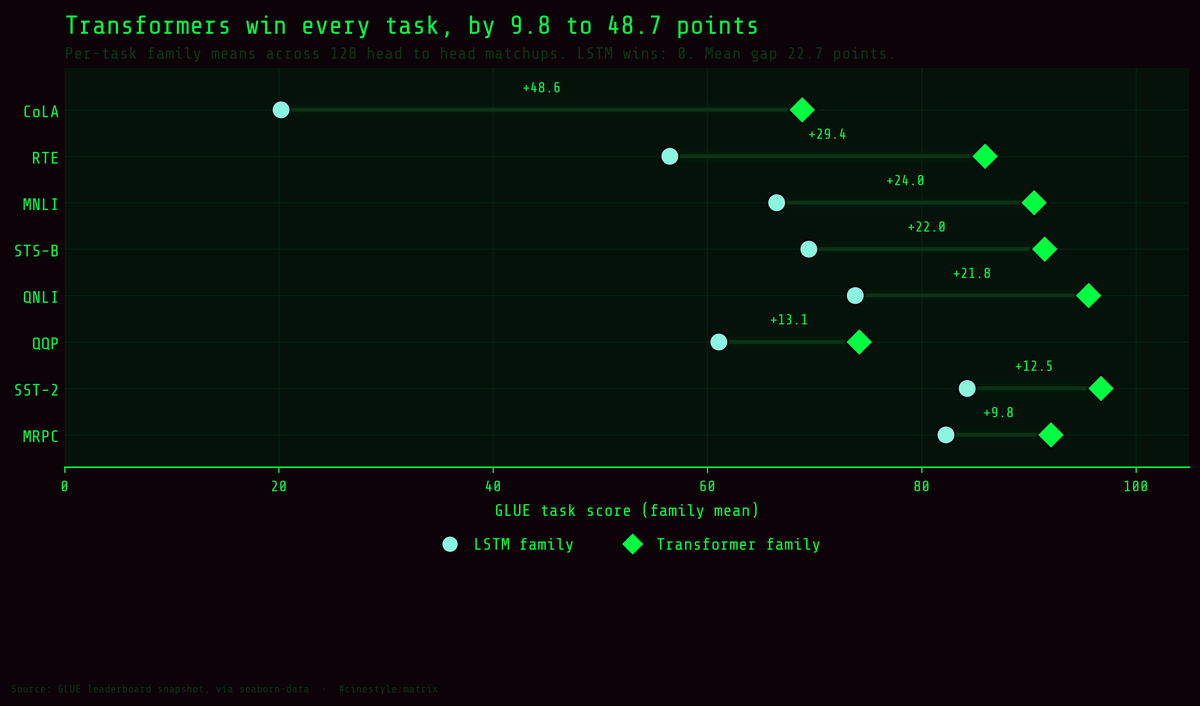
GLUE and the Transformer Leap
22.67 points: what the field bought by dropping the recurrence
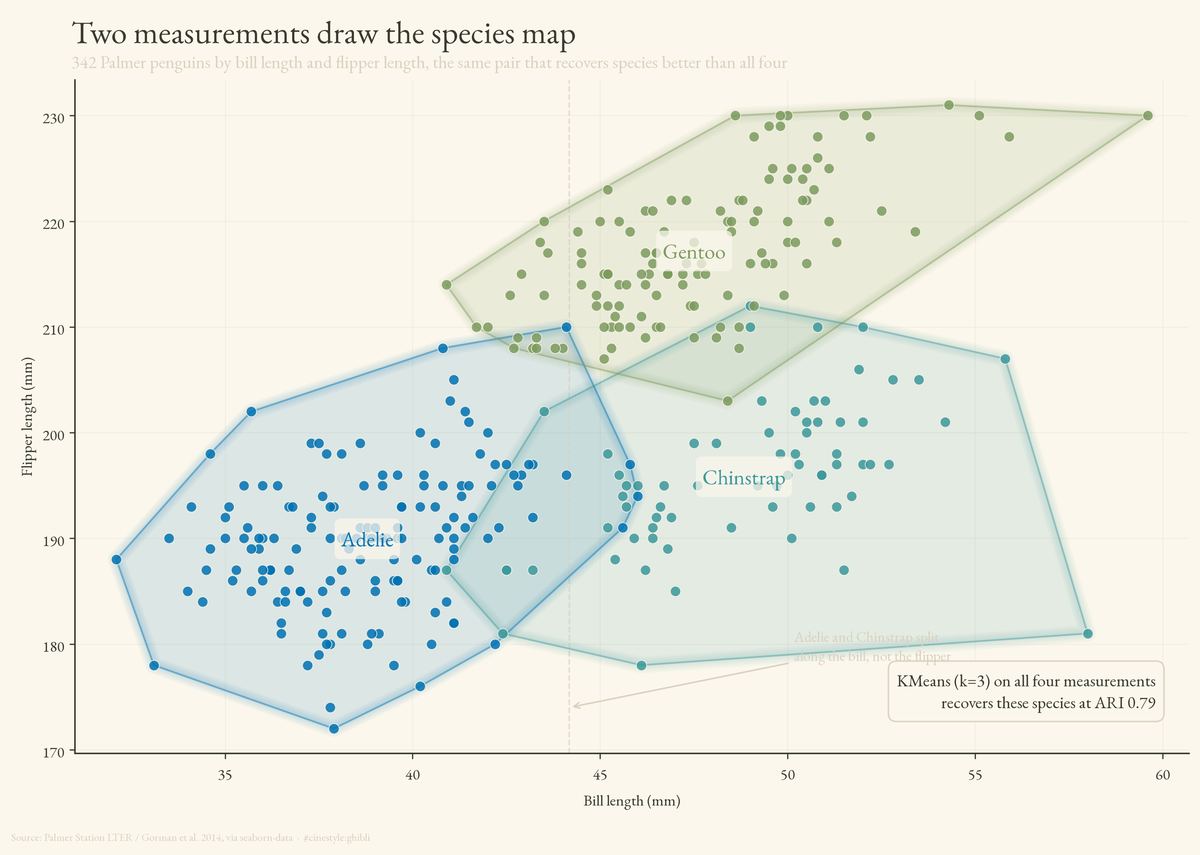
Clustering Penguins
Two penguin measurements beat four
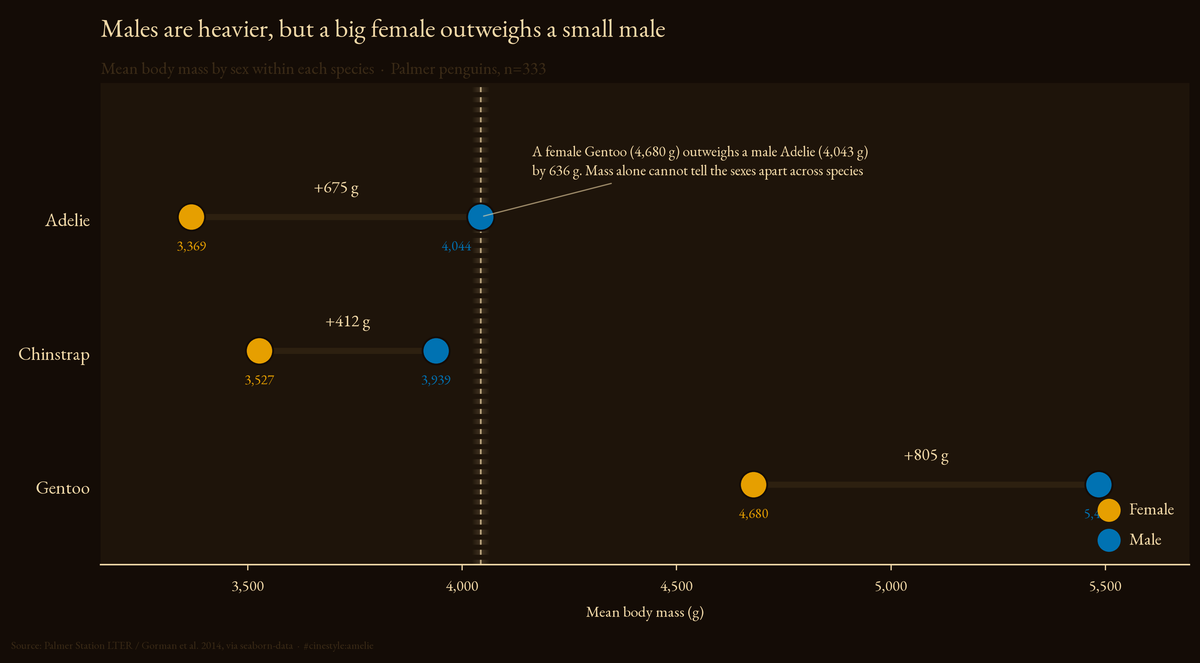
Penguin Dimorphism
A female Gentoo outweighs a male Adelie by 636 grams
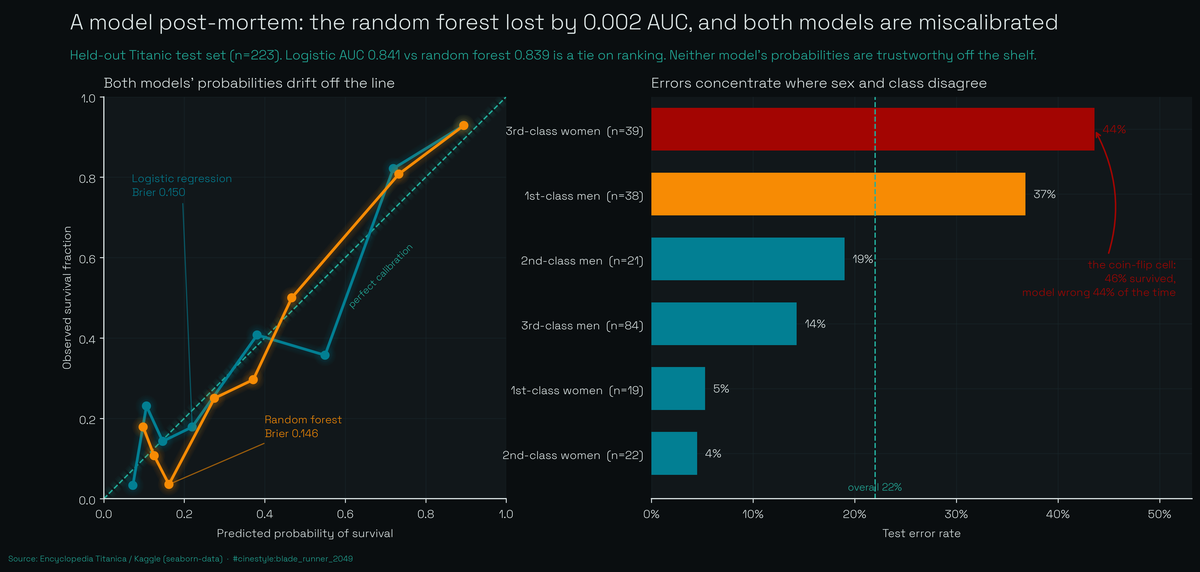
Predicting Titanic Survival
The random forest lost. By 0.002 AUC.
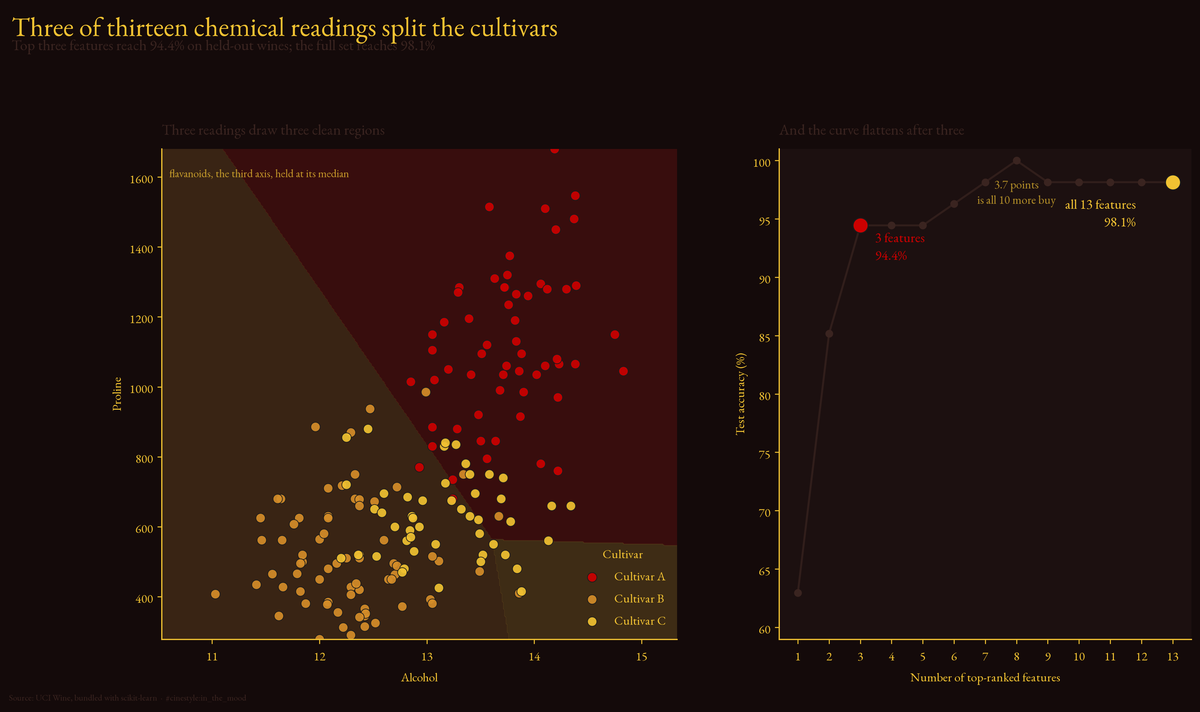
Classifying Wine
Three numbers off a wine label beat your fancy model
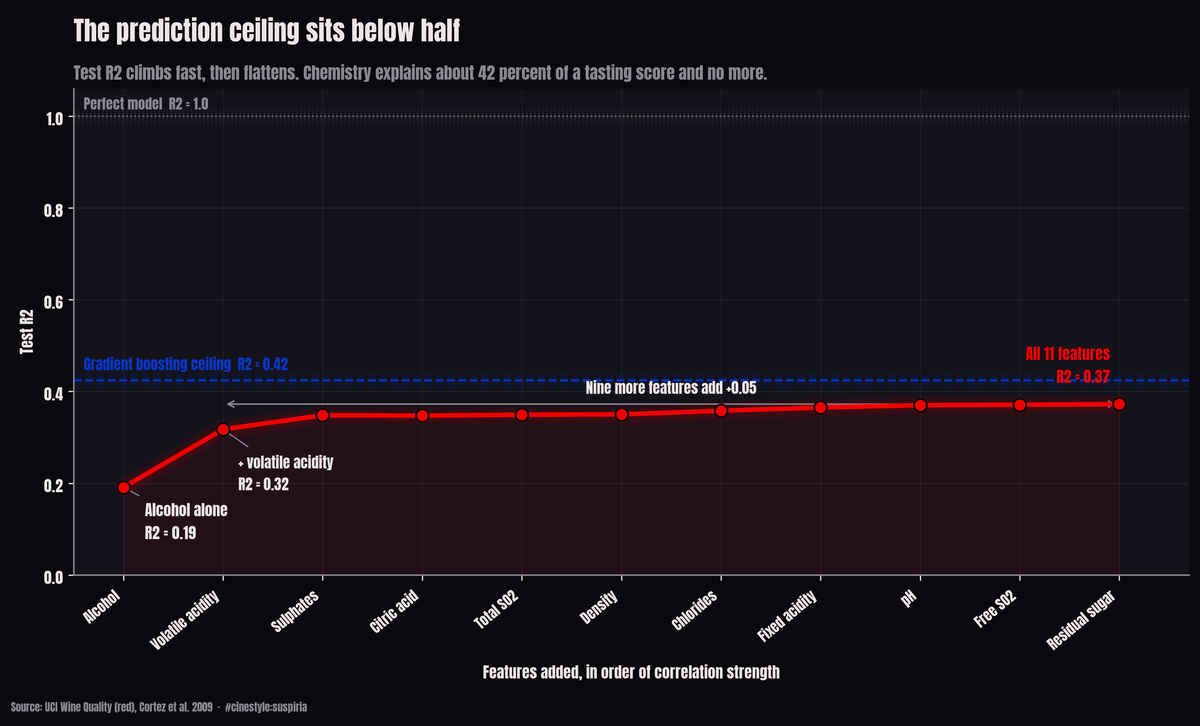
What Makes Wine Good
Wine quality is mostly just alcohol, and even that only gets you so far
Deploying ML in production: a working reference (Part 1)
Serving architectures, containerization, lifecycle management, performance optimization, drift detection, and monitoring — with benchmarks and code from production systems.
ML deployment: a working reference for getting models into production
A field-tested reference for taking ML models from prototype to production — serving patterns, containerization, monitoring, drift detection, and the operational practices that make the difference.
A local-LLM scraper for Chamber of Commerce directories
Built a pipeline that extracts 296 businesses from Chamber of Commerce directories in 9 minutes using a local 7B-parameter model — 100% name/phone capture, no API costs.
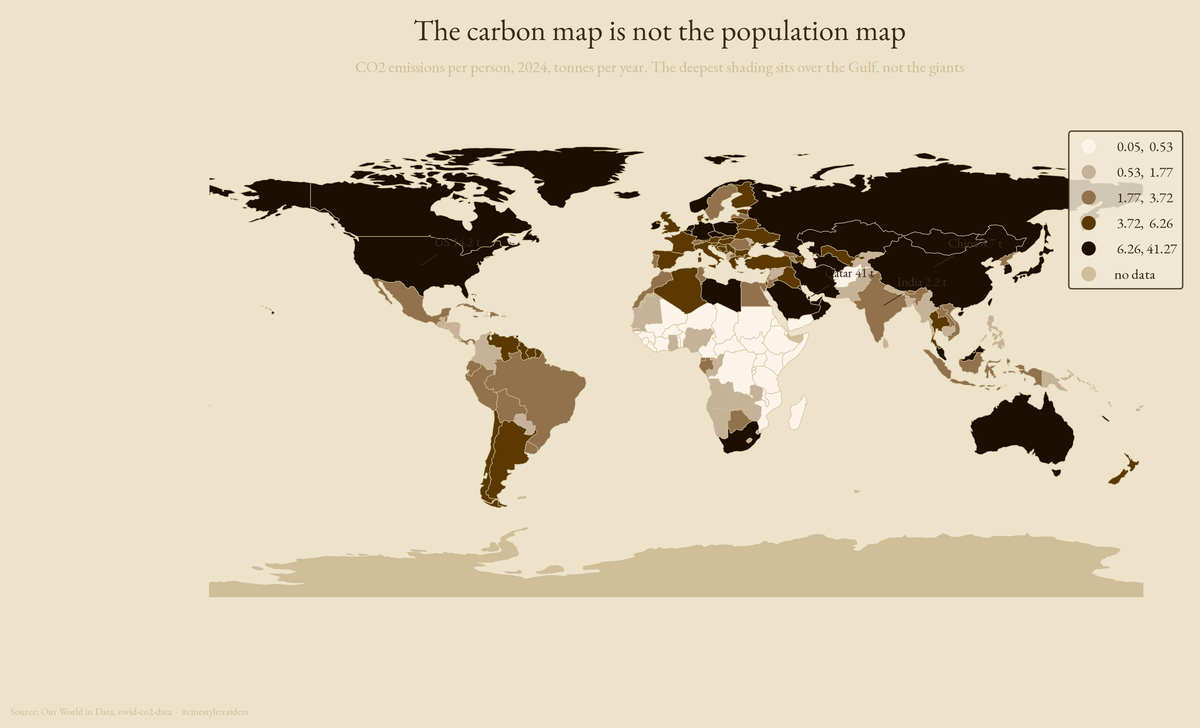
Who Emits the Carbon
Who actually emits the carbon, and the answer depends on how you count
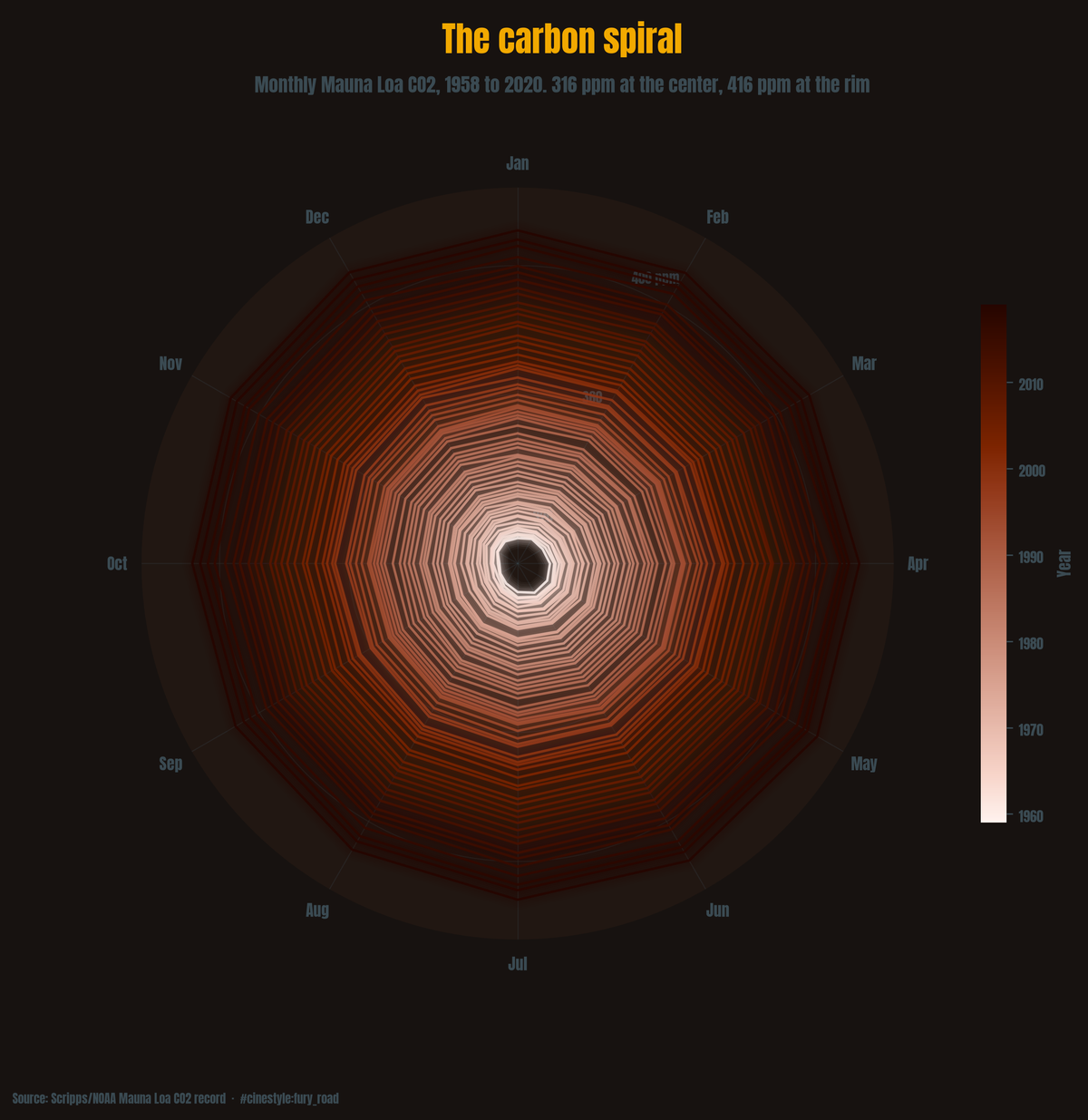
The Accelerating CO2 Curve
The CO2 rise is speeding up, and the curvature is the story
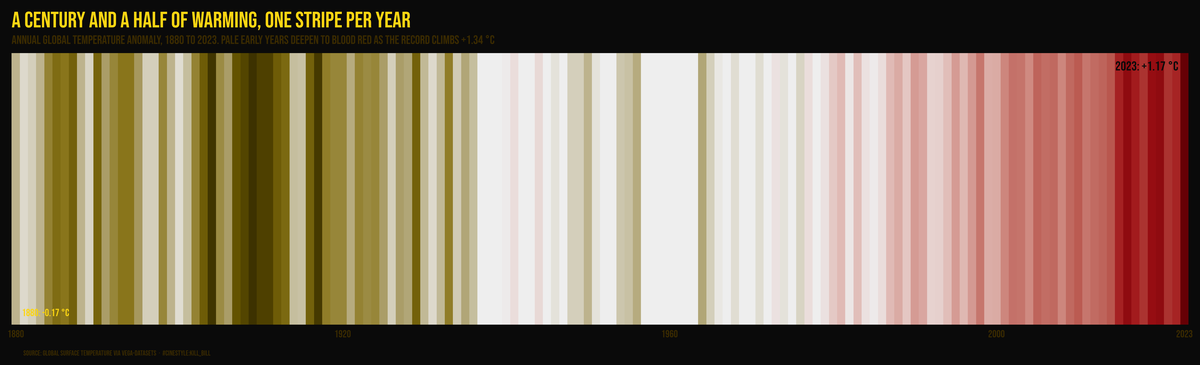
The Warming Rate
The warming rate has sextupled, and the line cannot keep up
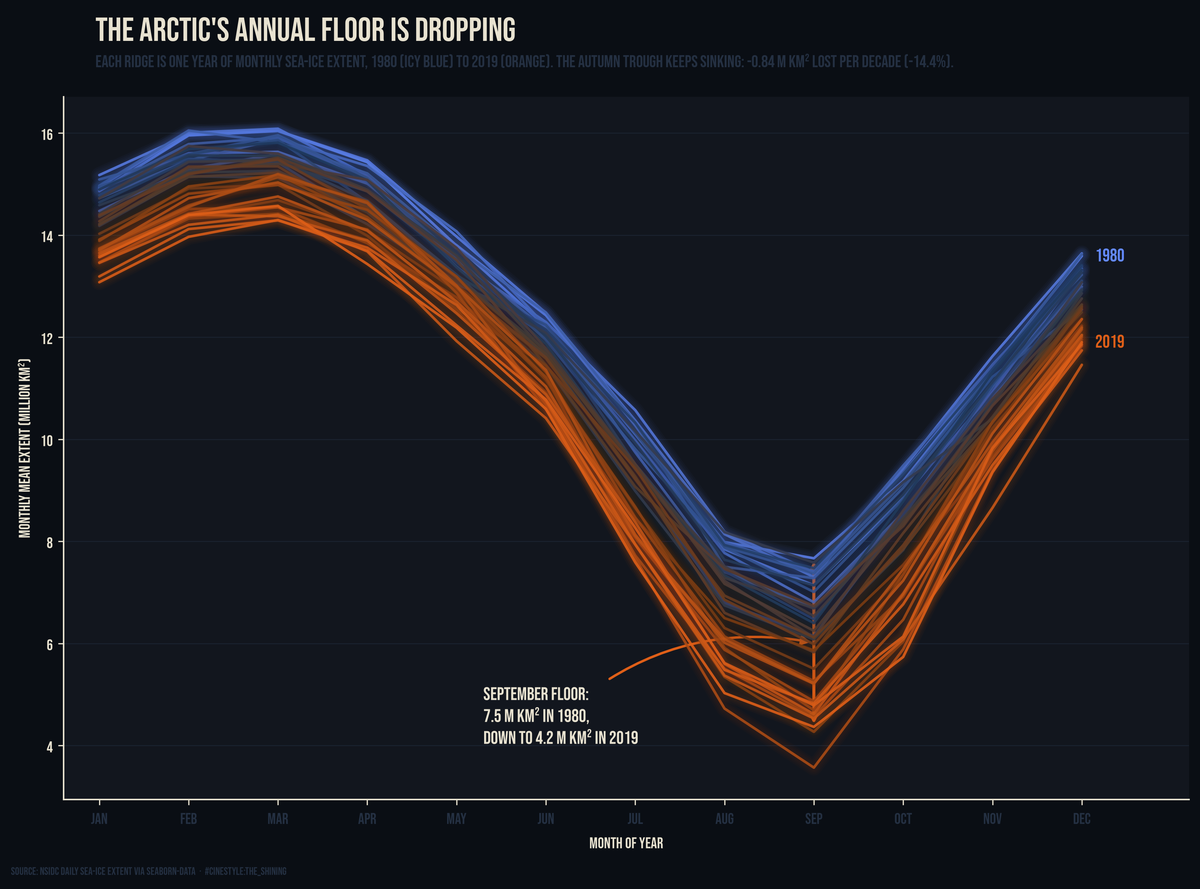
The Arctic's Shrinking Ice
The Arctic's September floor is dropping 0.84 million km² a decade

A World Map of Drinking
A world map of drinking, and what the colors give away
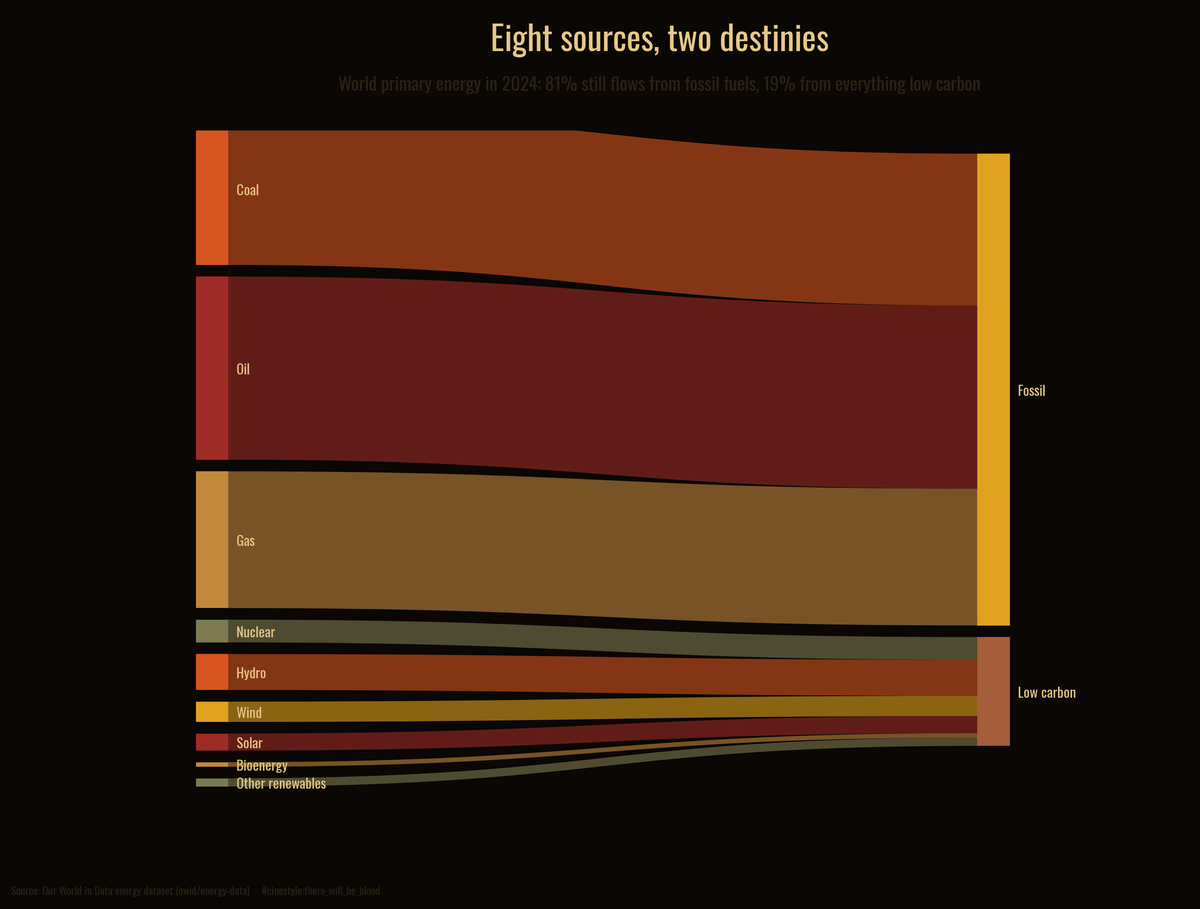
Where Energy Comes From
Where the world's energy actually comes from
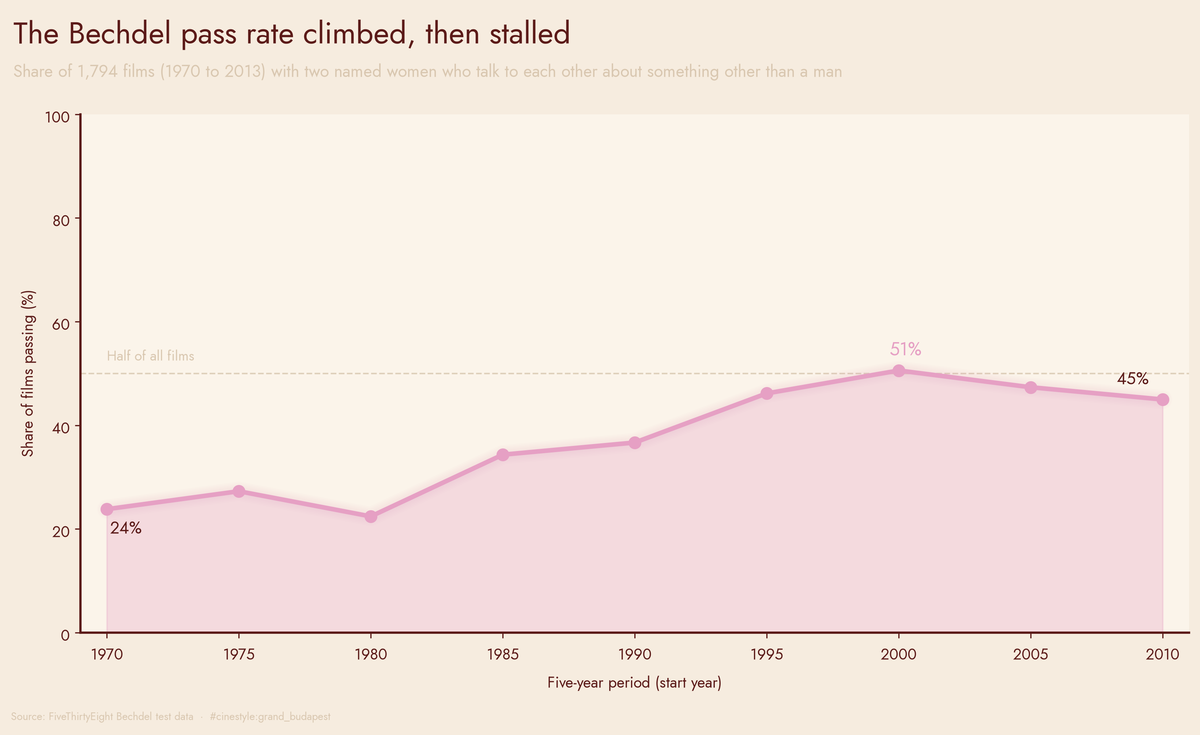
The Bechdel Test at 50
The Bechdel test at 50: the pass rate climbed, then stopped
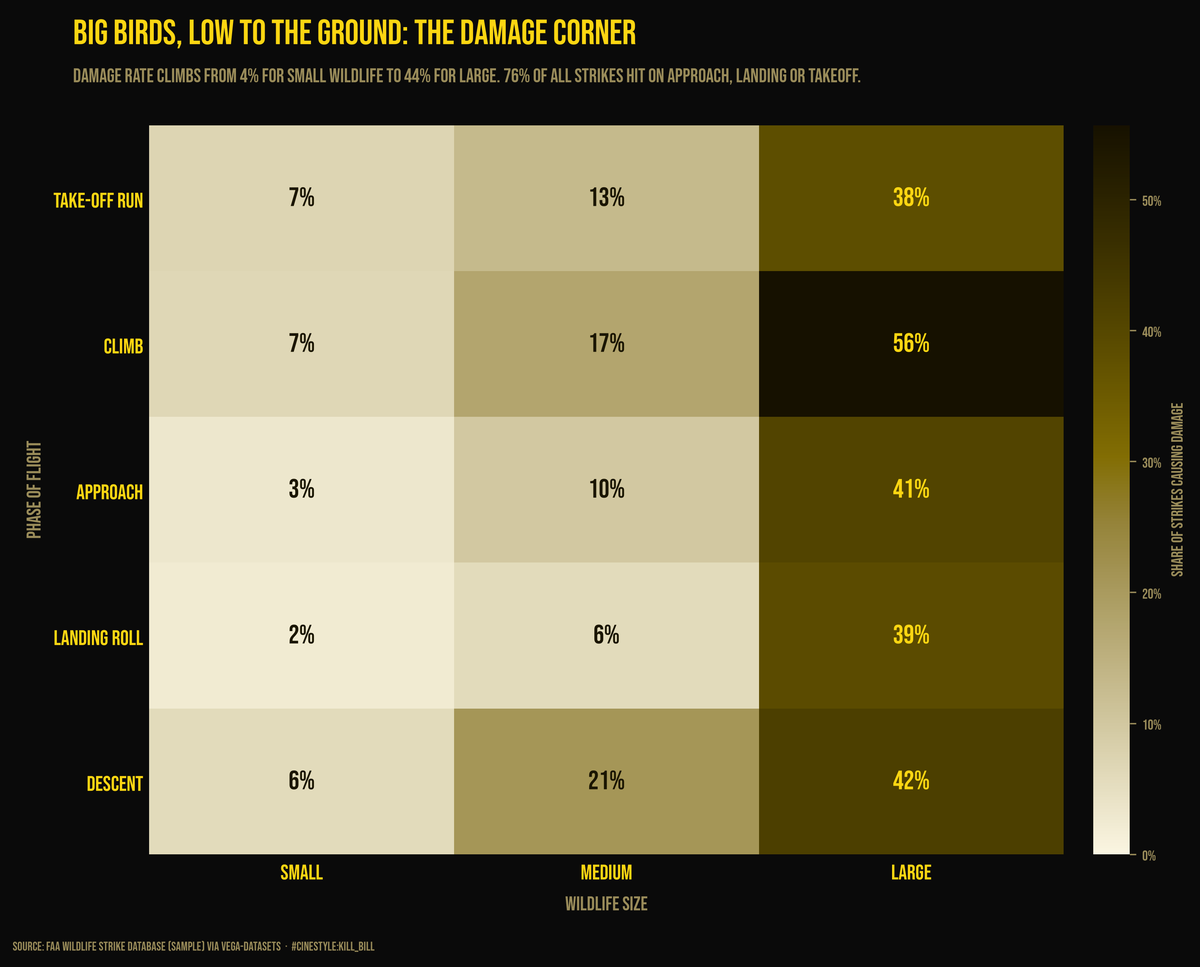
Bird Strikes on Approach
Birds do not hit planes at cruise. They hit them on approach.
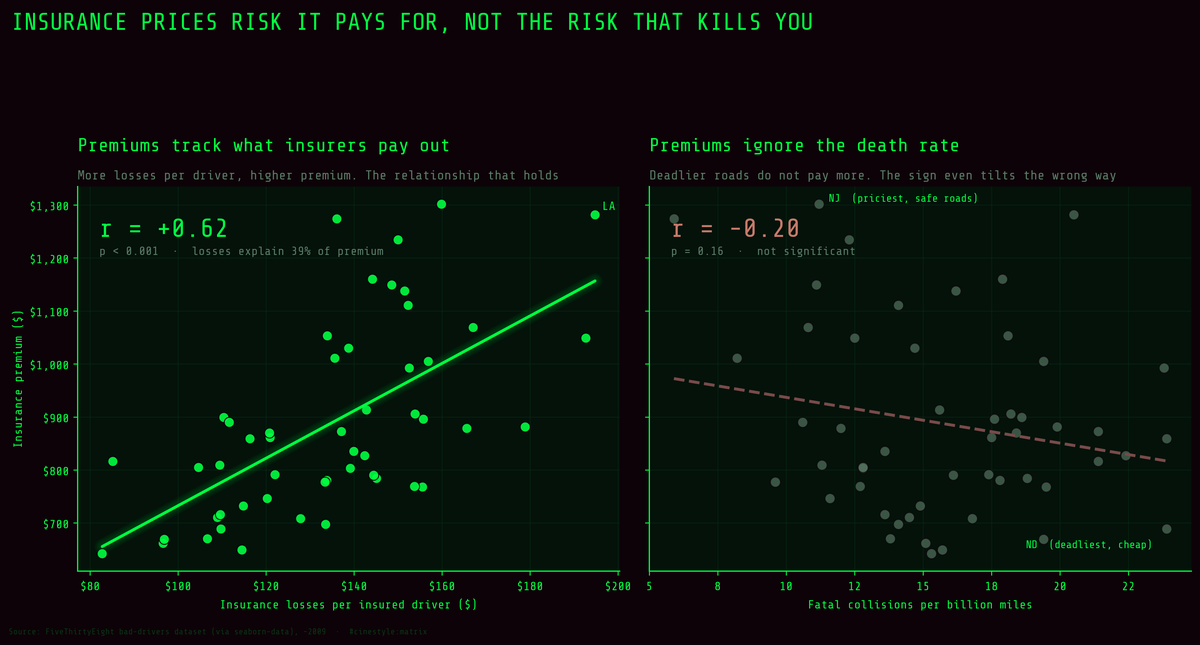
Premiums and Road Risk
Higher insurance premiums do not mean more dangerous roads
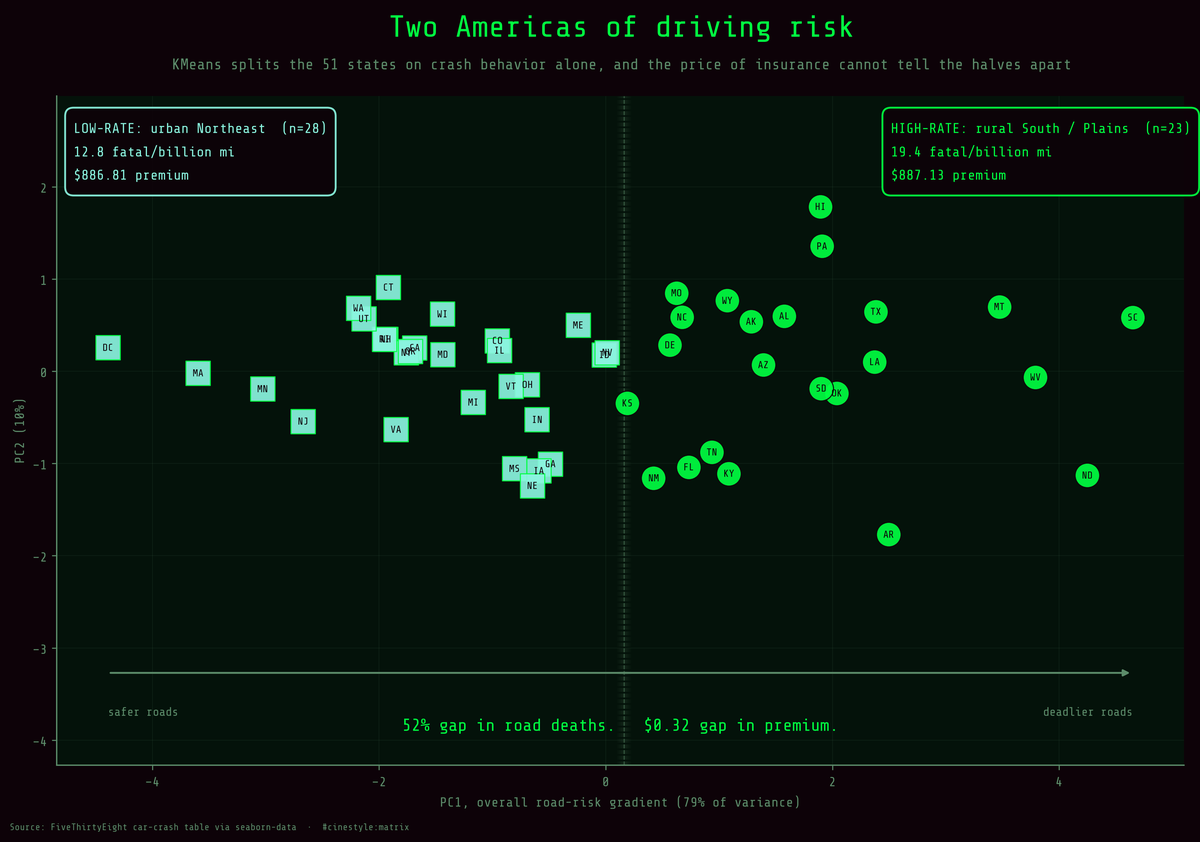
Two Americas of Driving Risk
Two Americas of driving risk, and the insurer charges them the same
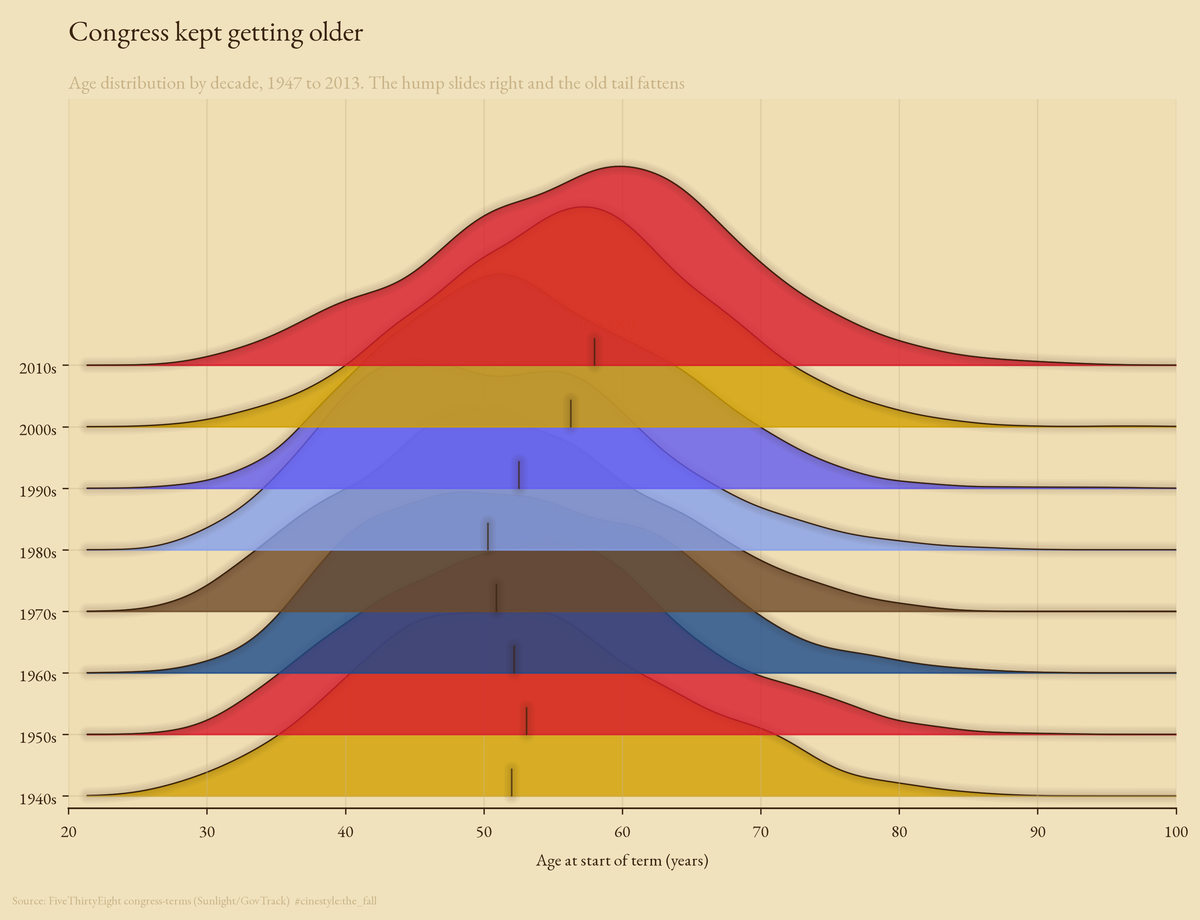
The Aging of Congress
Congress got older, but it took a detour first

Disease in the Crimea
In the Crimea, disease killed eight soldiers for every one the enemy did
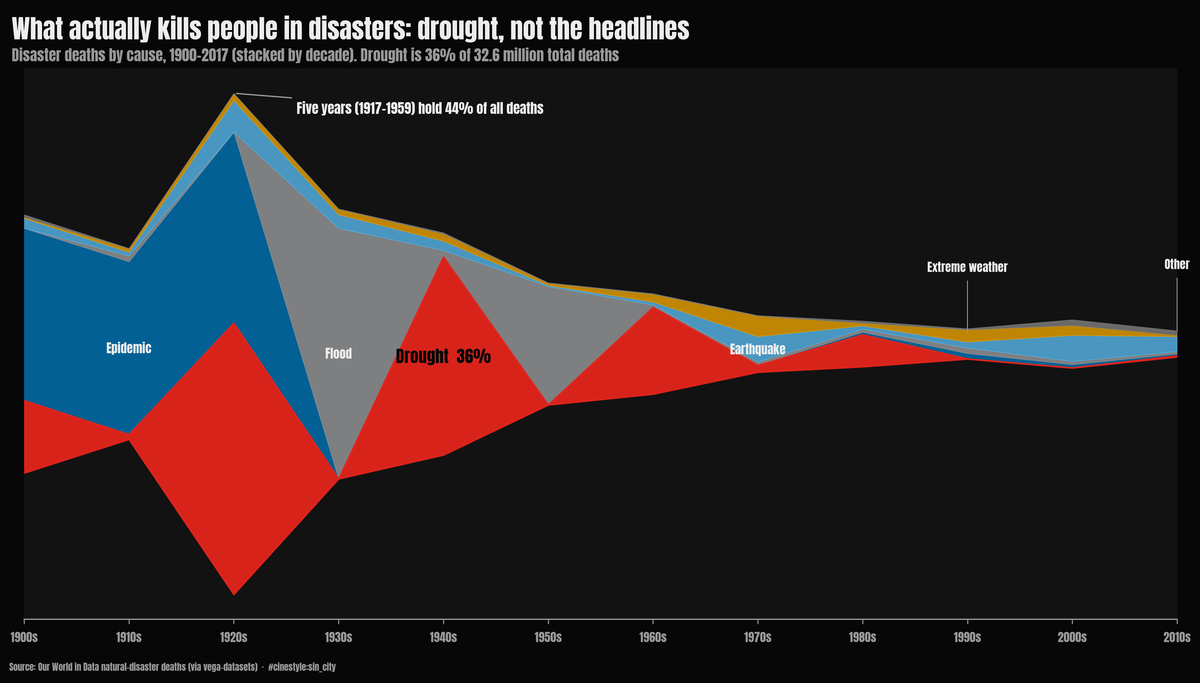
A Century of Disasters
Five years killed 44% of everyone who died in a natural disaster since 1900
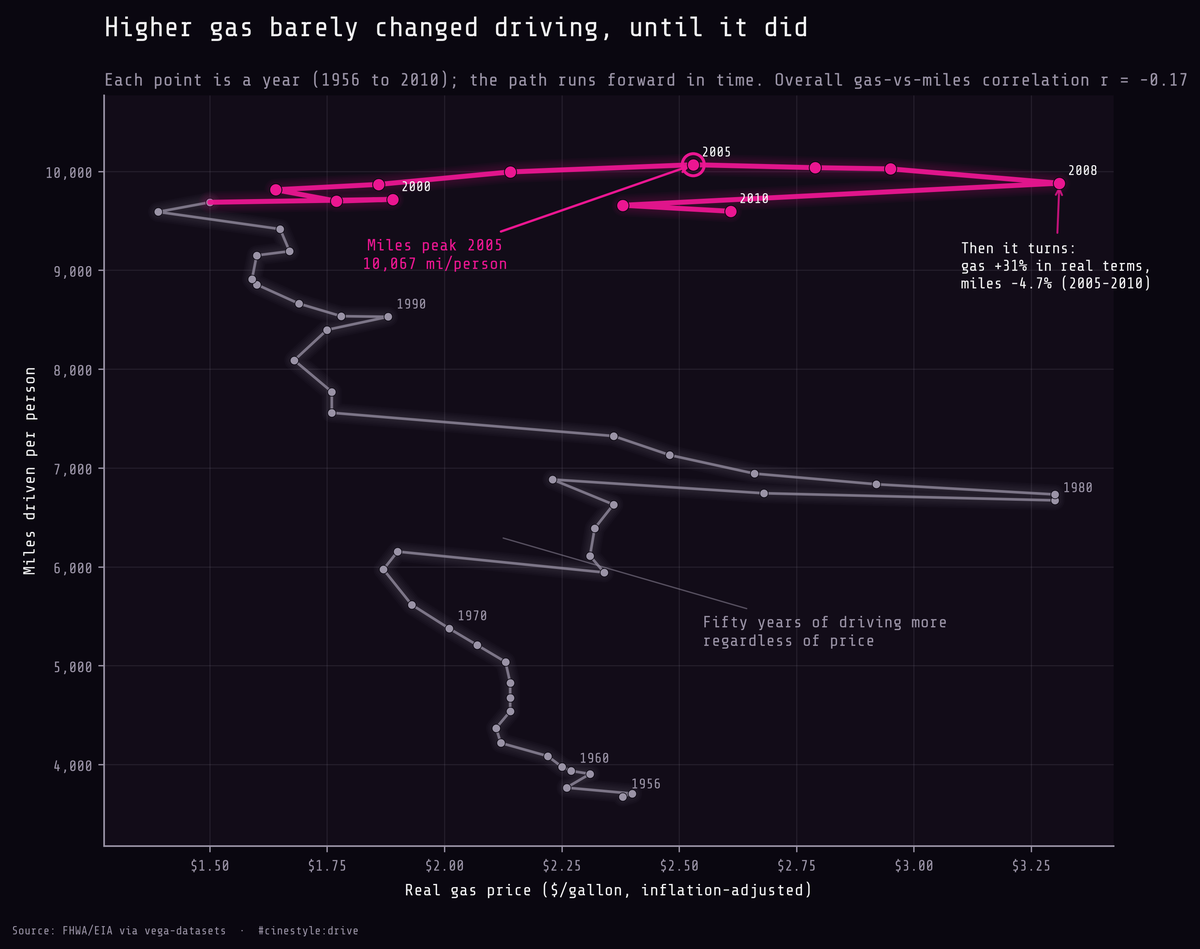
Gas Prices and Driving
For fifty years, gas prices barely changed how much Americans drove
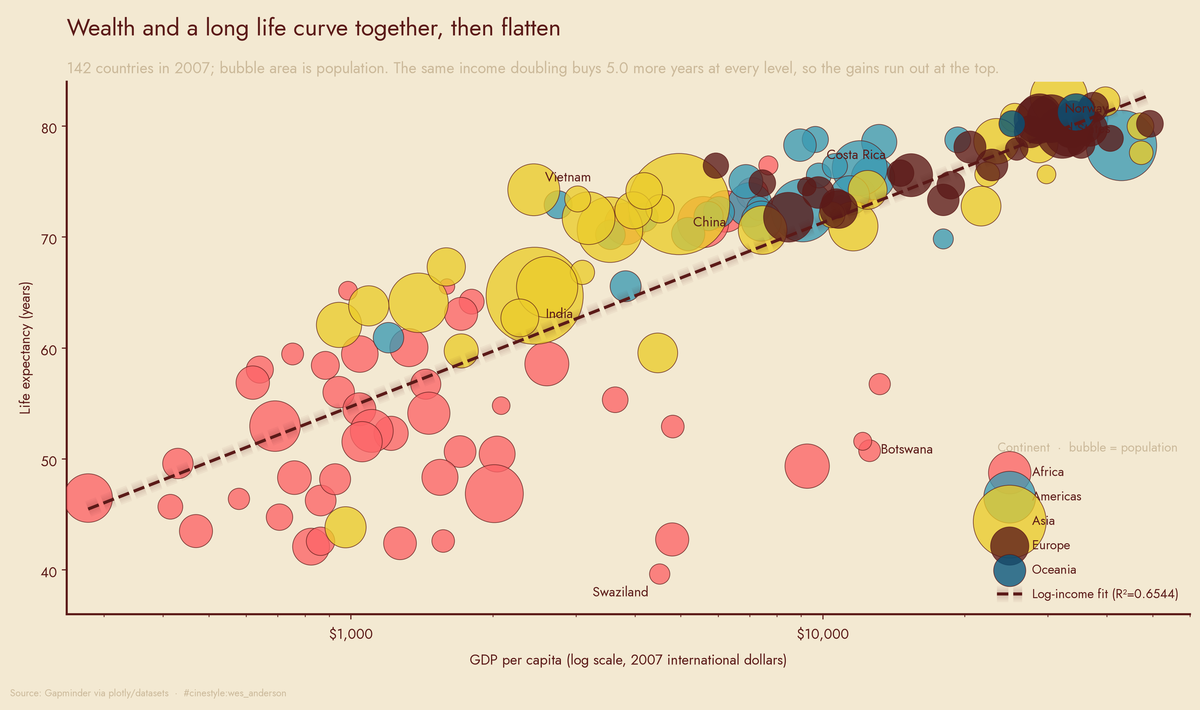
Money and Life Expectancy
Money buys life expectancy, but the receipt is brutal
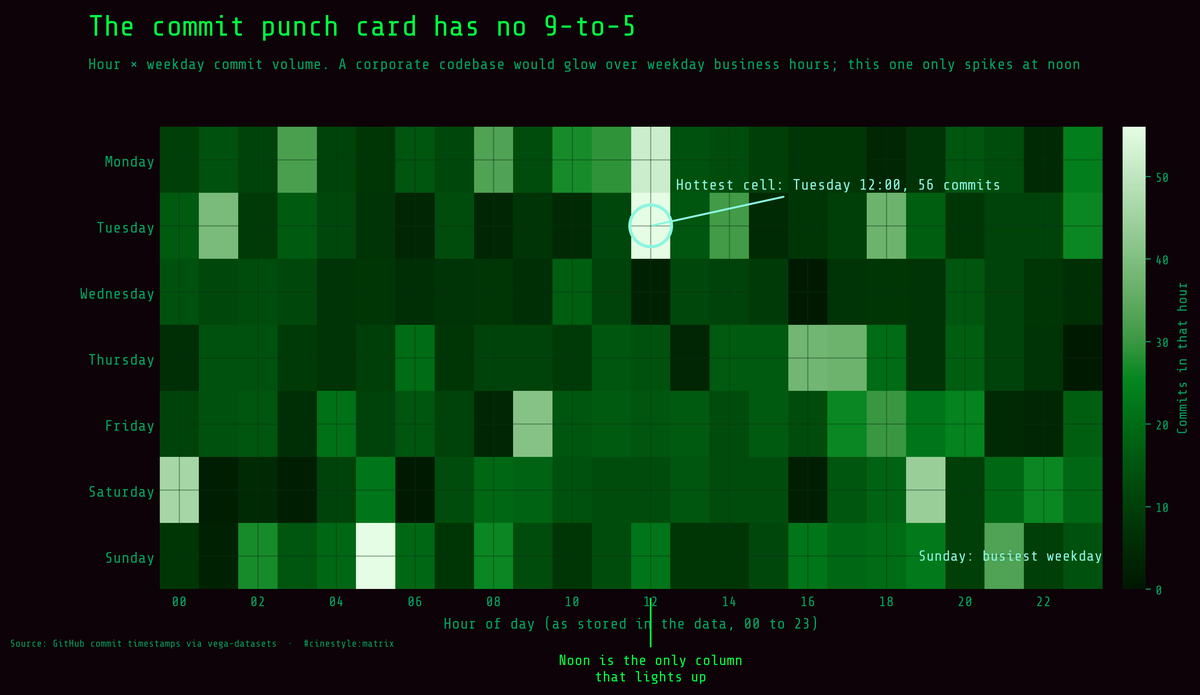
When Coders Commit
The 9-to-5 I went looking for was not in the commits
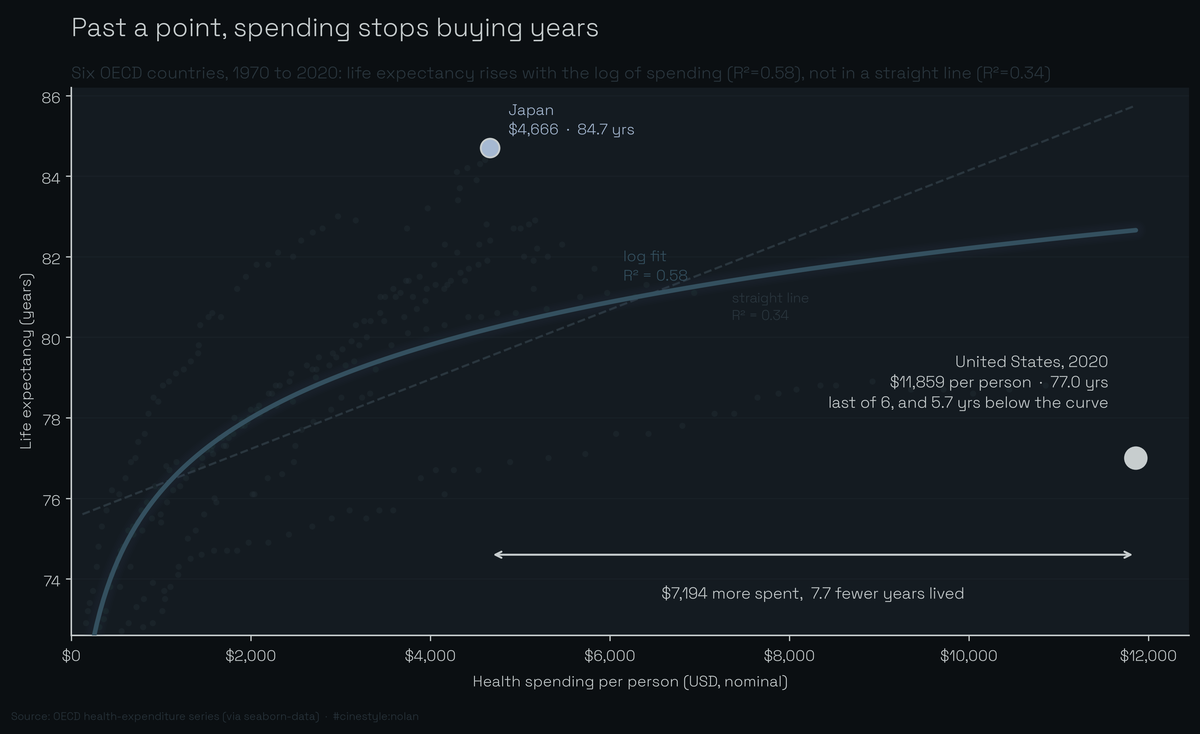
US Health Spending
The US spent $7,194 more per person than Japan and died 7.7 years sooner
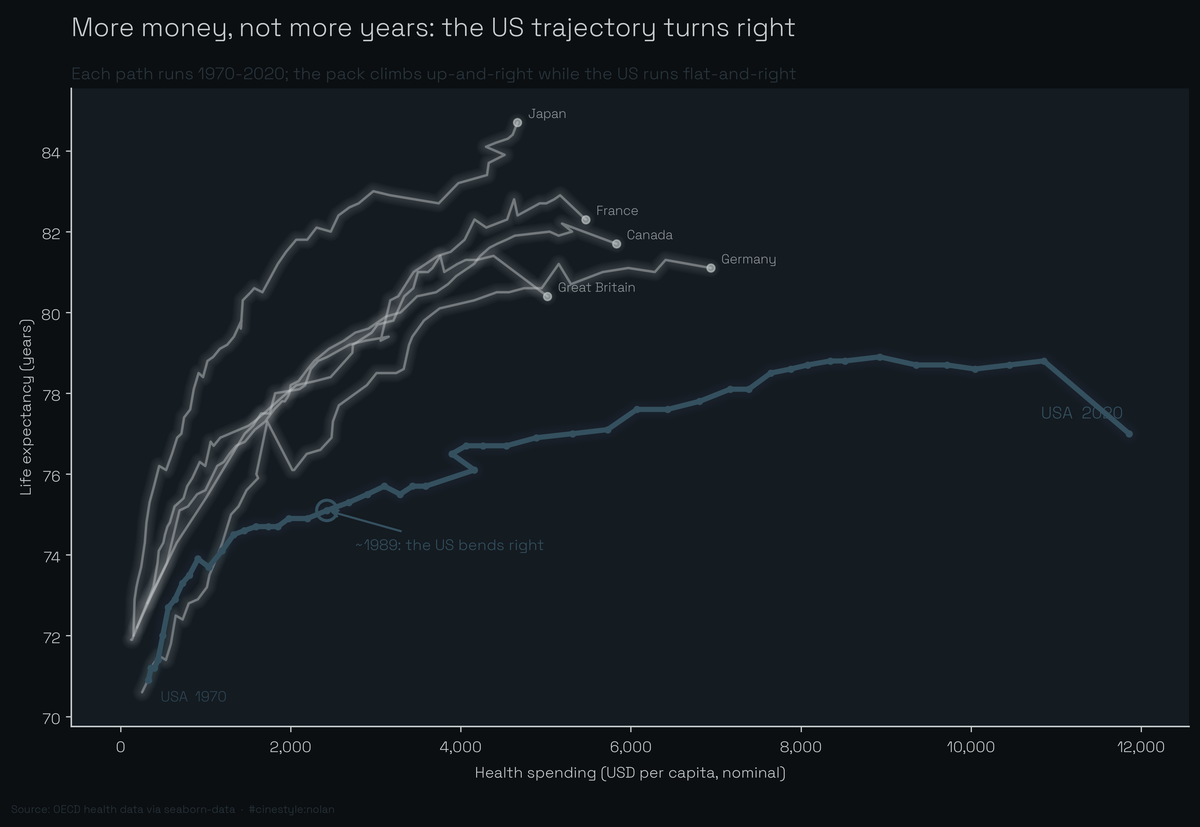
The Health-Spending Gap
In 1991 the US health-spending gap crossed $1,000 and never came back
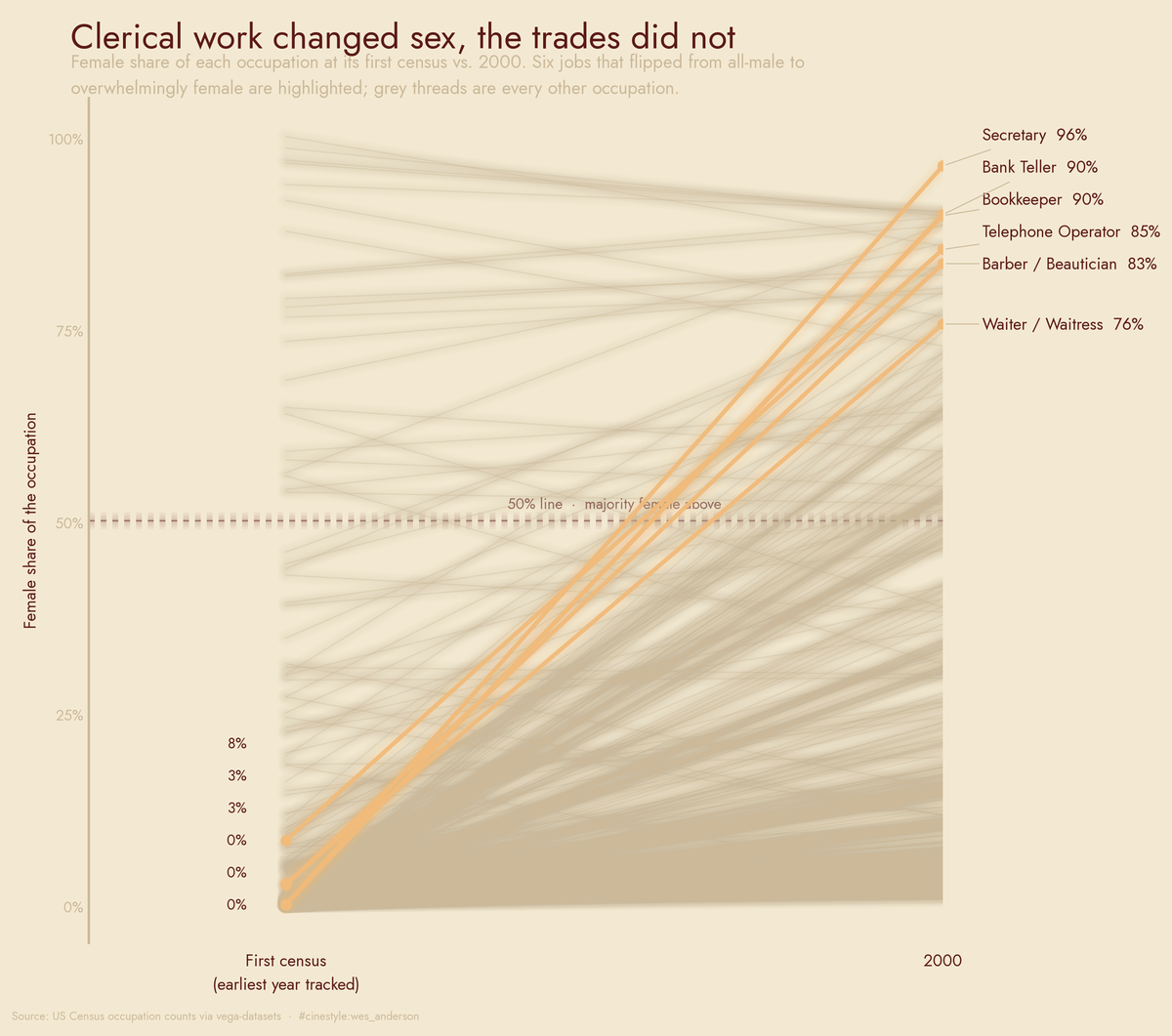
Jobs That Switched Gender
The job that went from all-male to 96% female
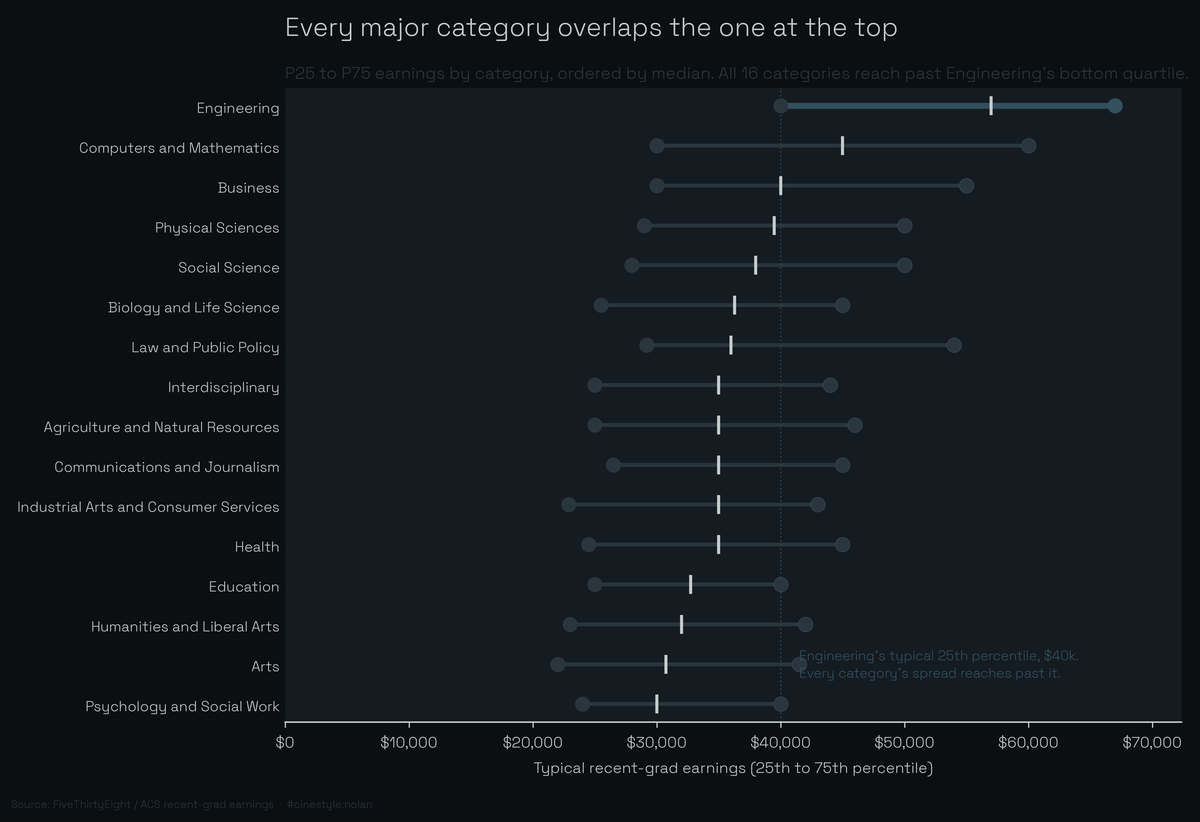
College Majors and Pay
Your major sets the odds, not the salary
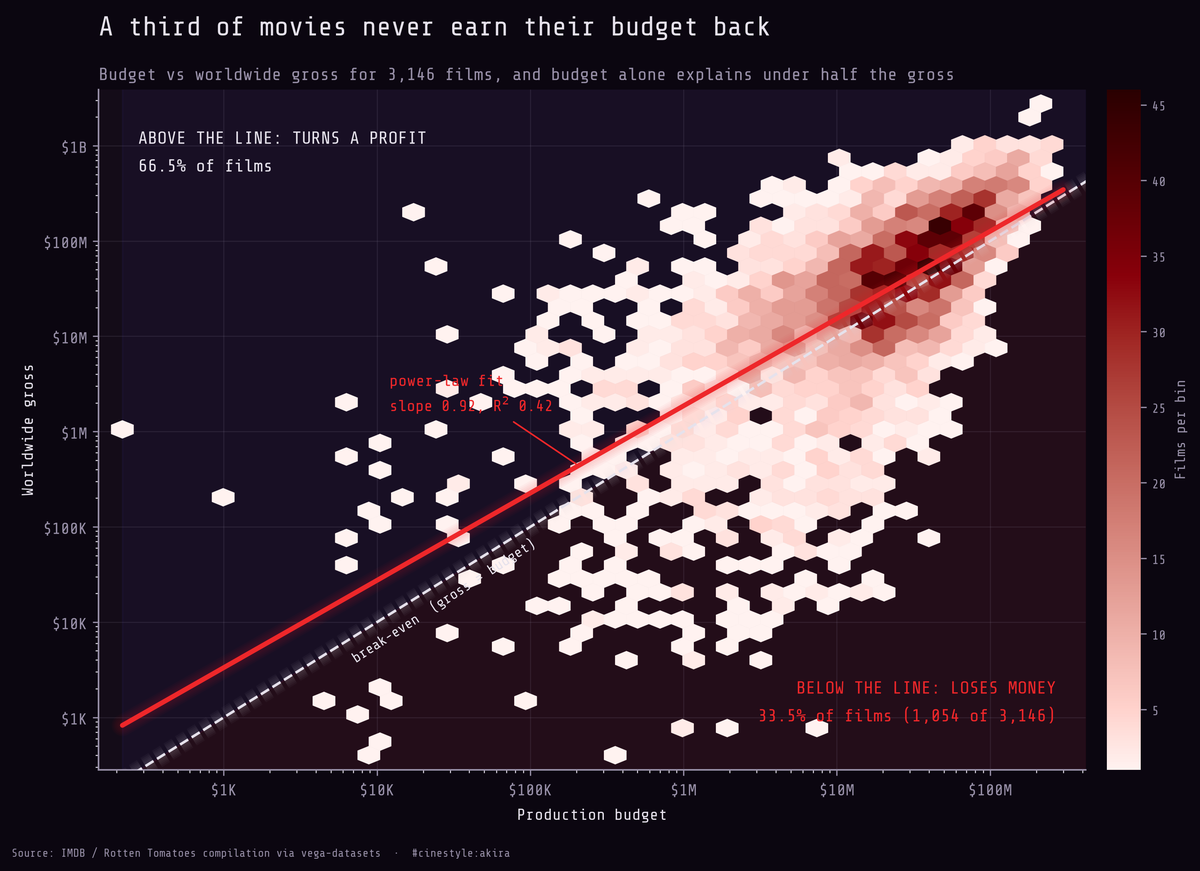
Box-Office Economics
Spend more, make more, but a third of films lose money anyway
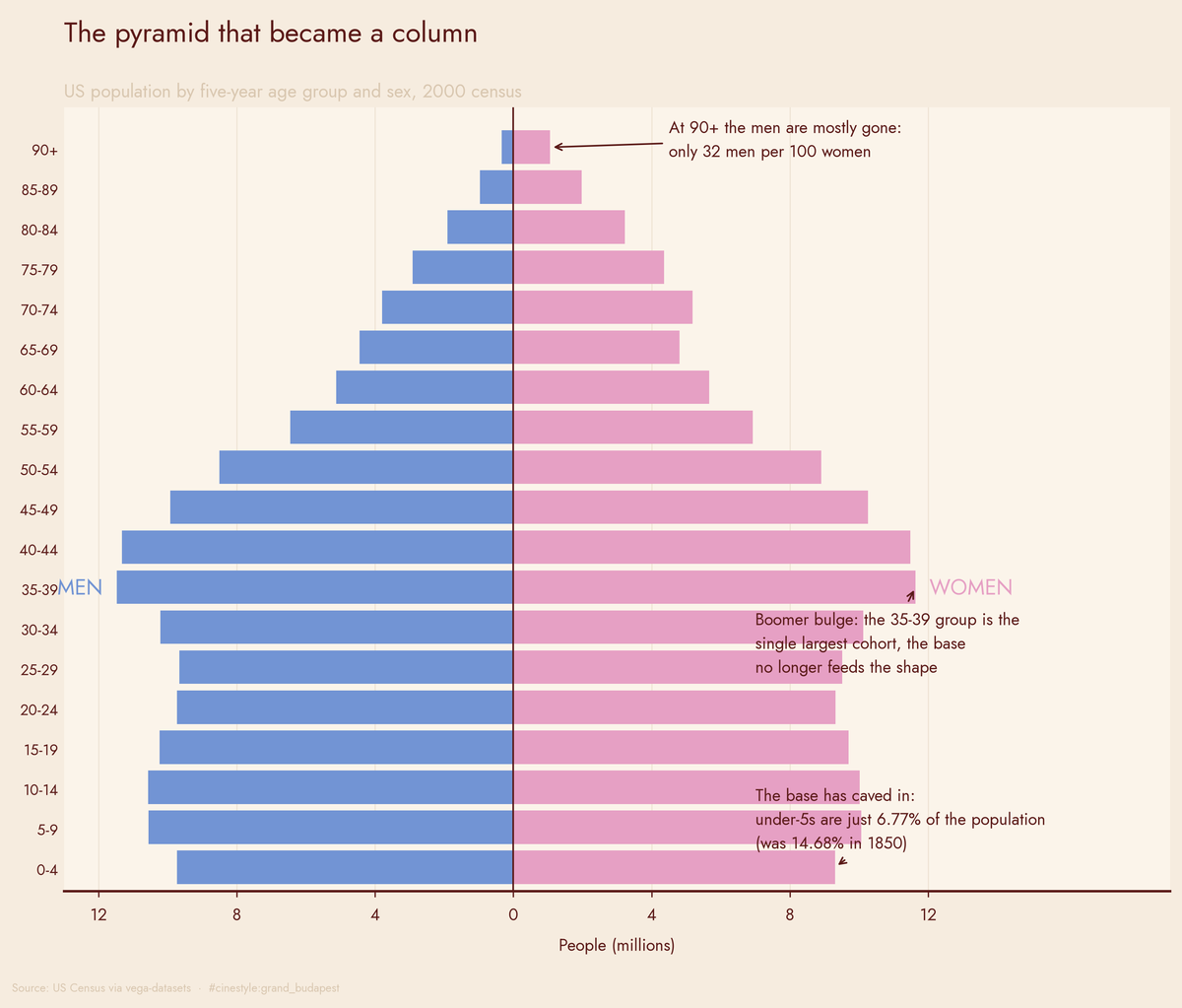
Aging and Sex Ratios
At 90, there are three women for every man
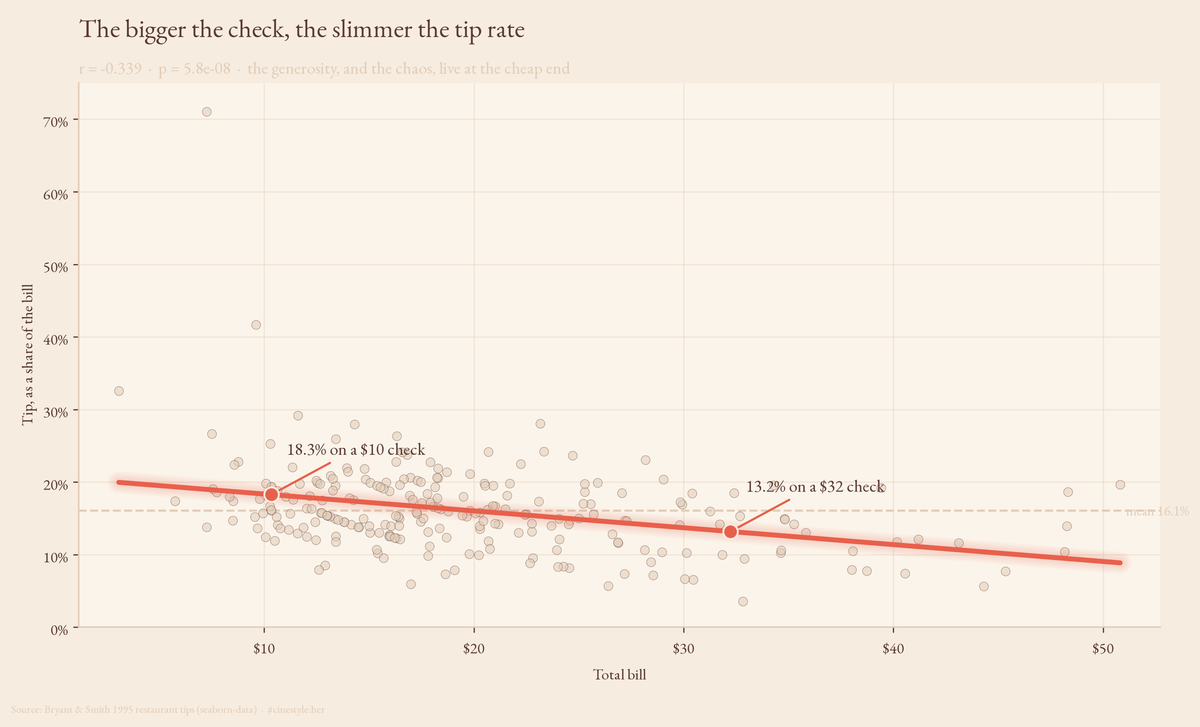
How People Tip
Tip 18.6% on a small check, 13.3% on a big one
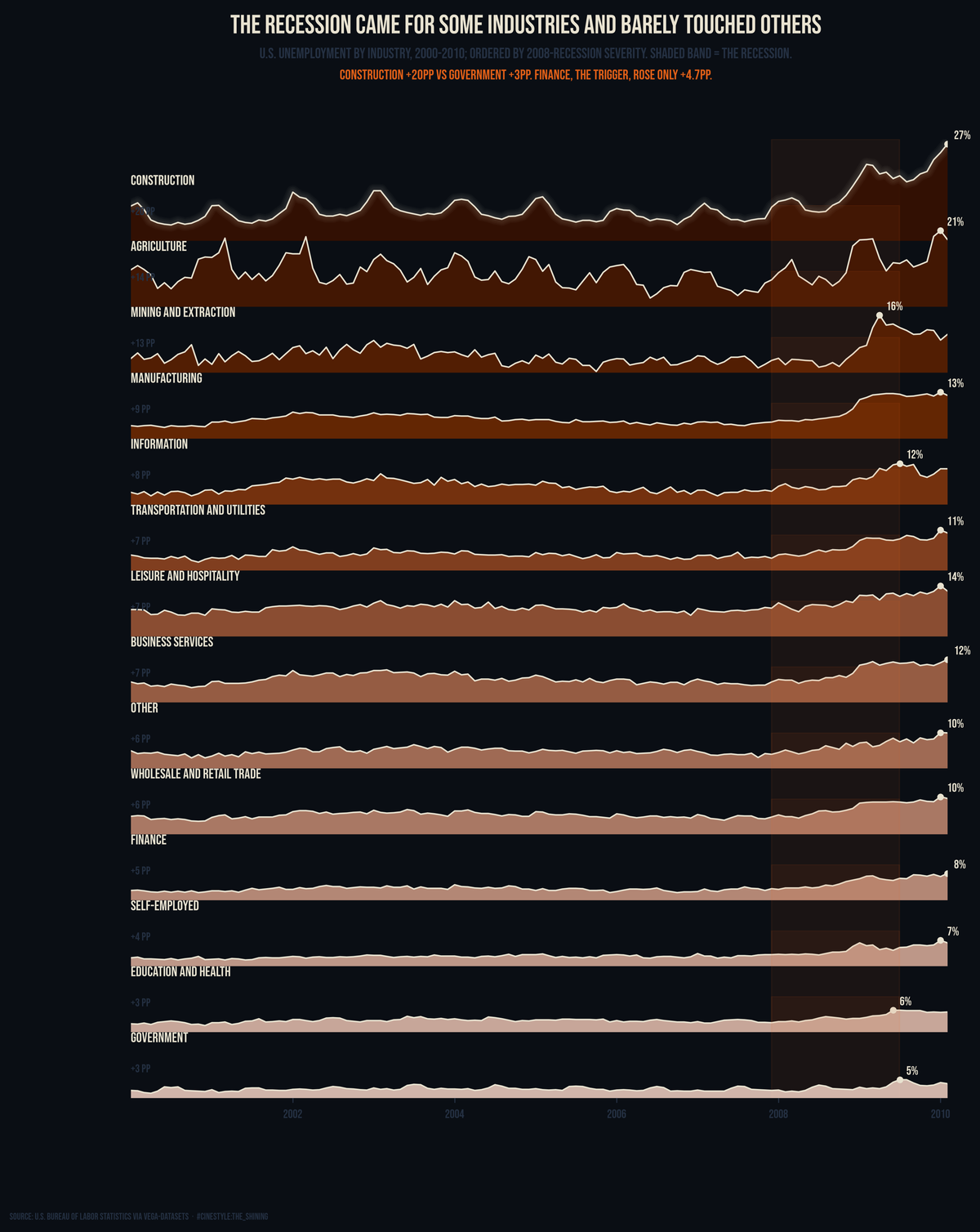
Unemployment by Industry
Construction hit 27% unemployment. Government never cracked 6.
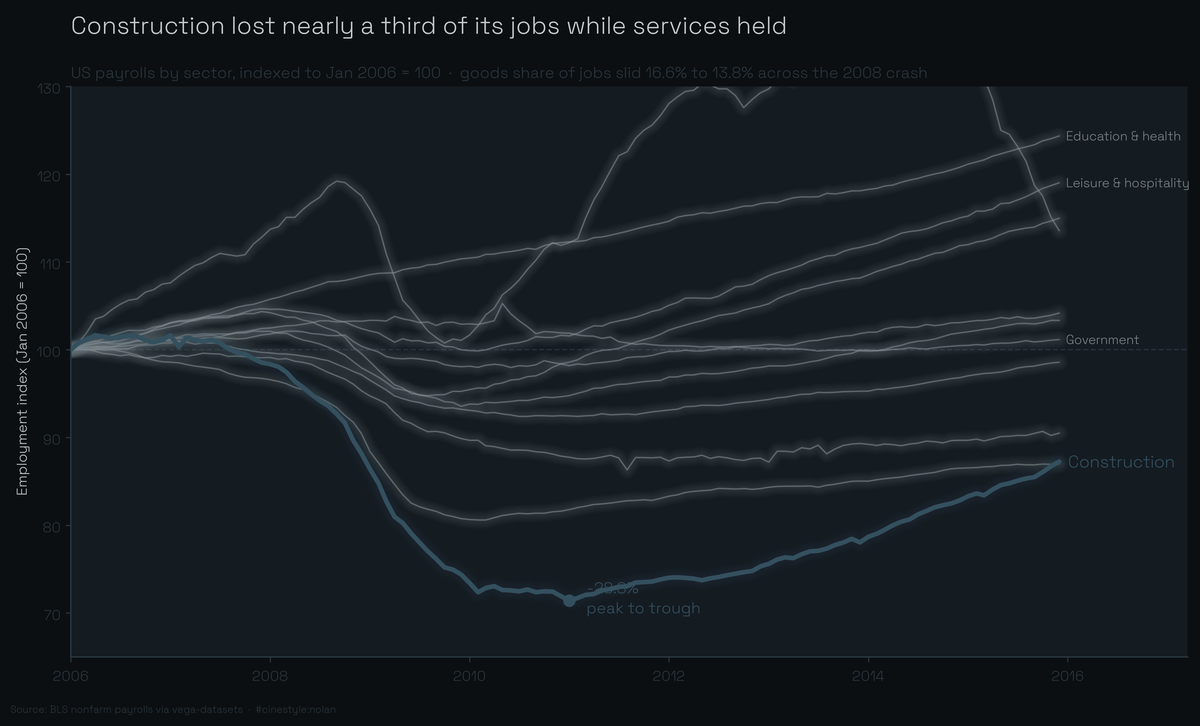
The Jobs That Vanished
Construction lost almost a third of its jobs, and never got them back
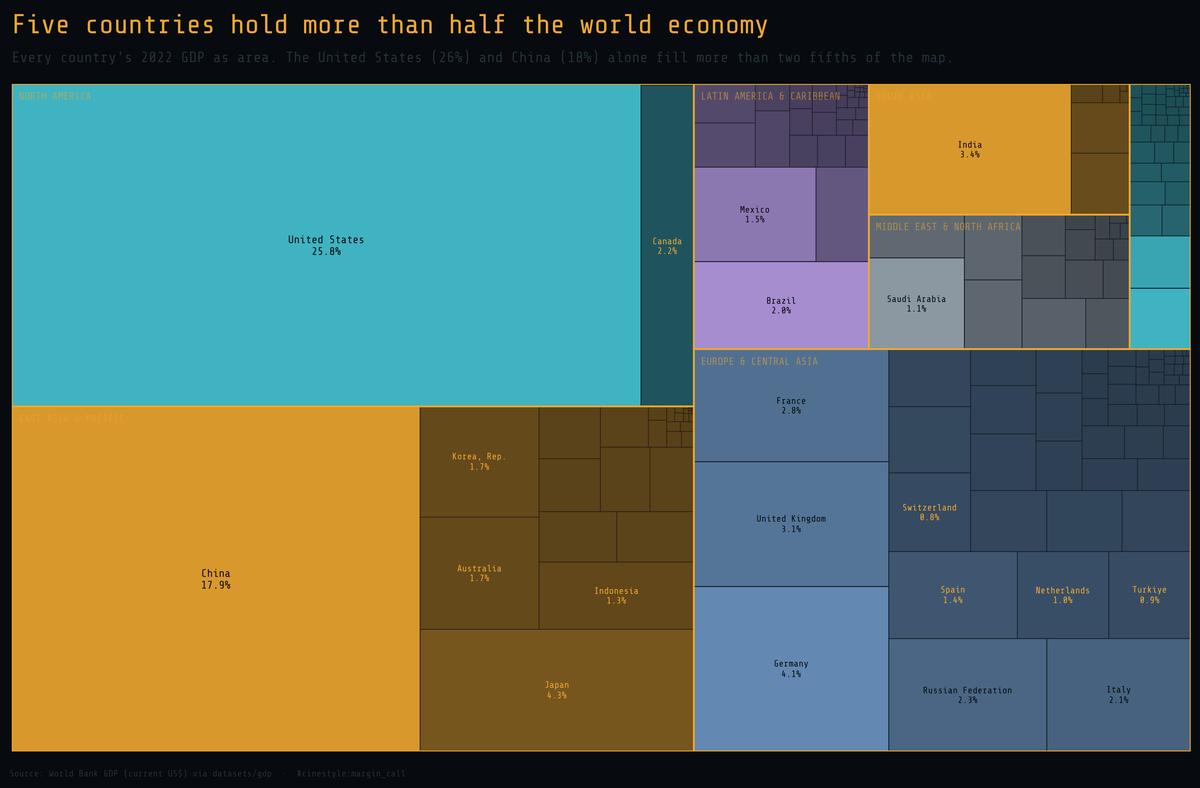
Who Owns the Economy
Five countries own half the world economy
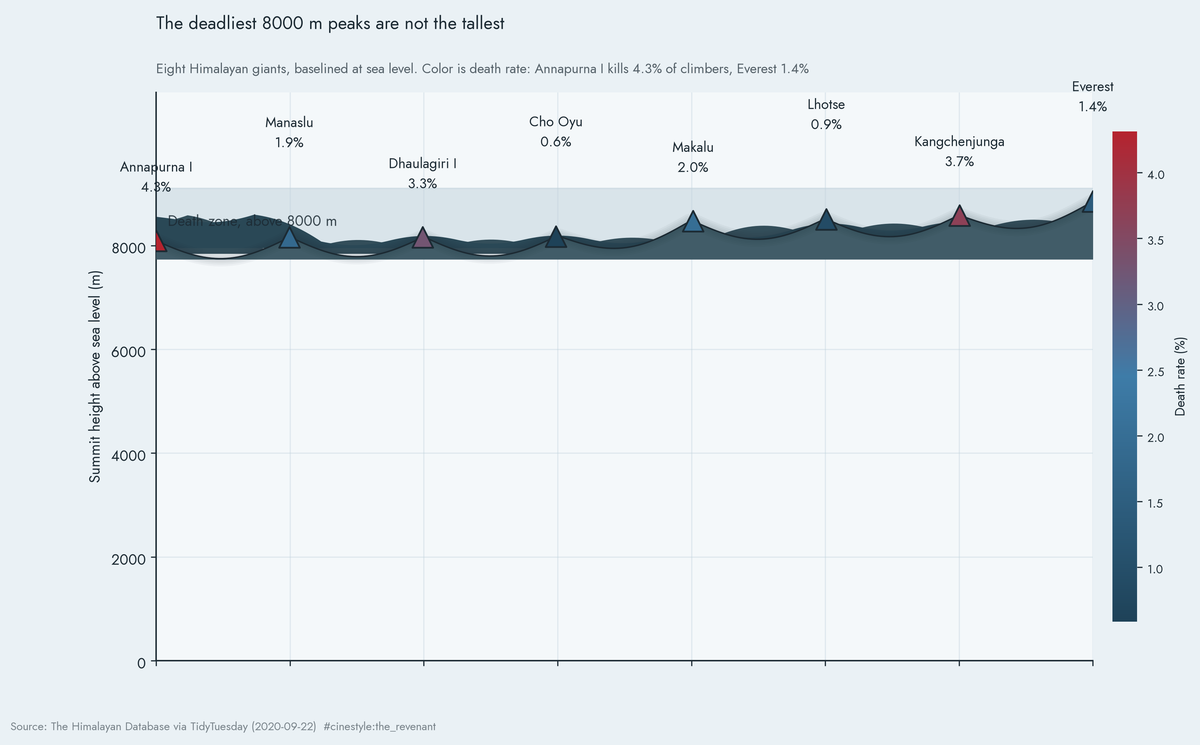
The Deadliest Mountains
The deadliest mountain is not the one you think
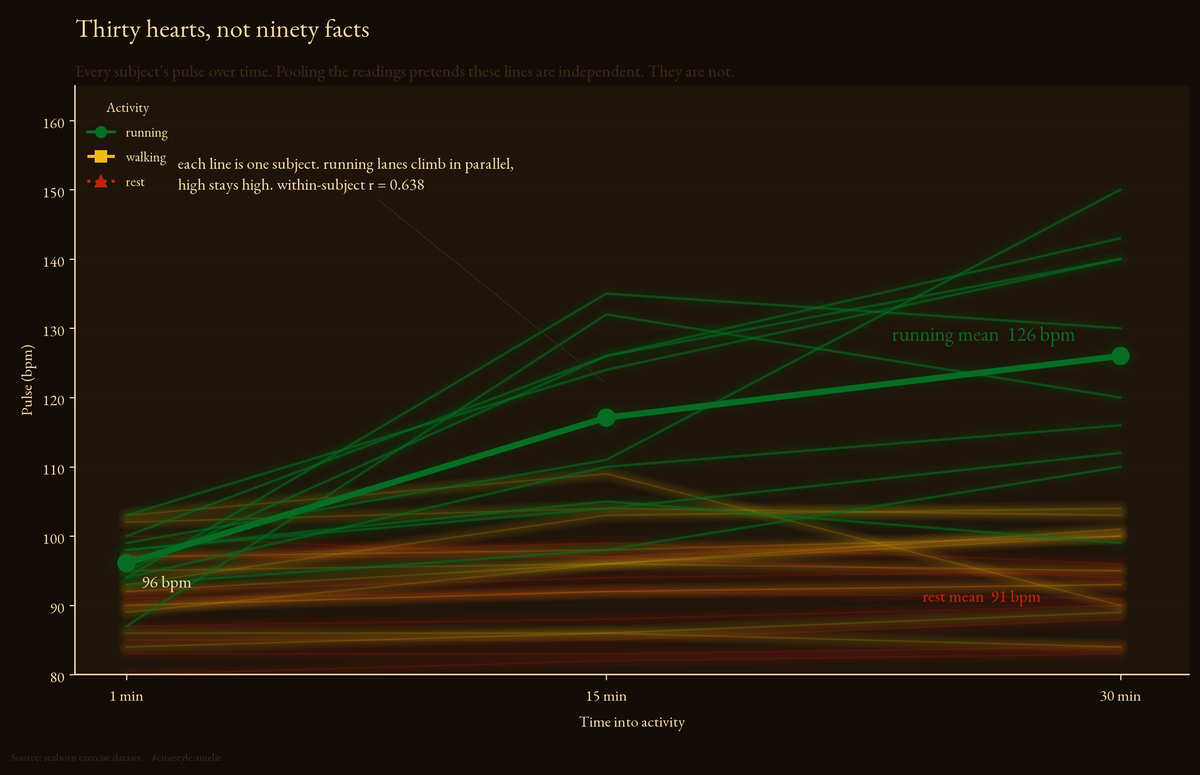
Pulse Under Exertion
Thirty people, ninety pulses, and one mistake everyone makes
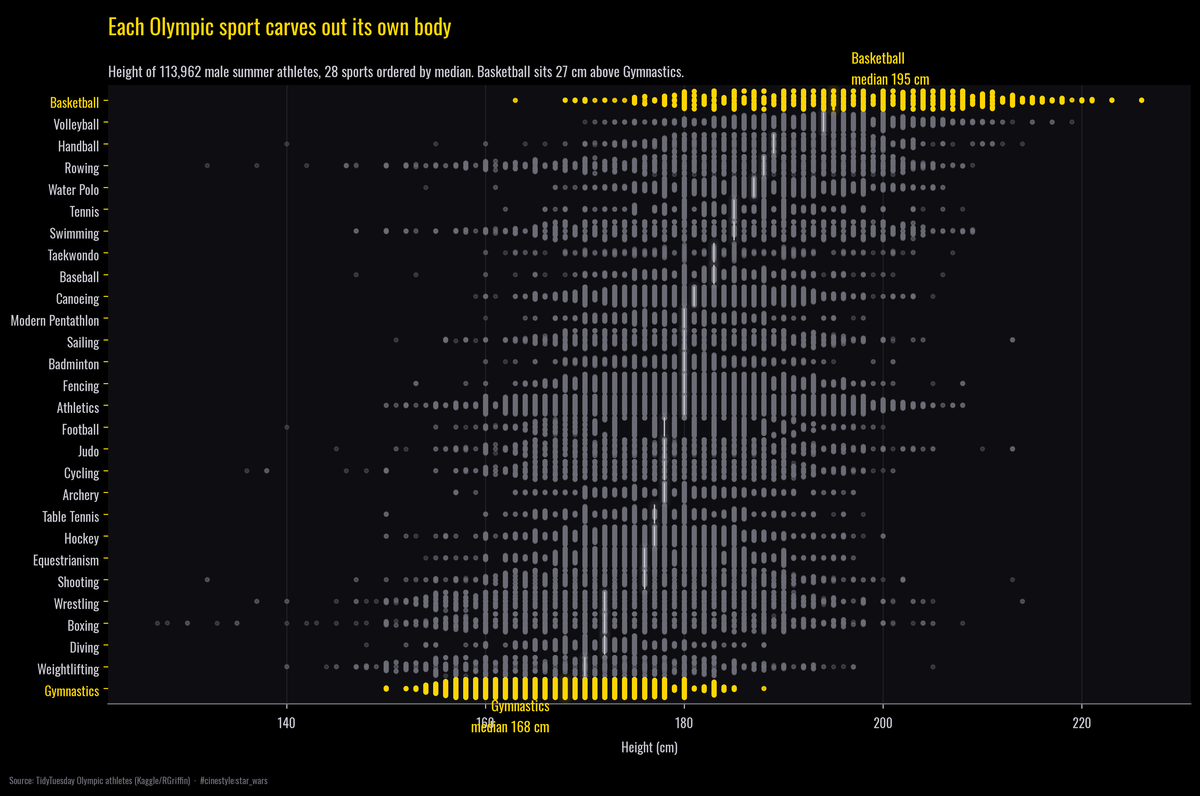
The Olympic Body
The body an Olympic sport builds, and how it sharpened over a century
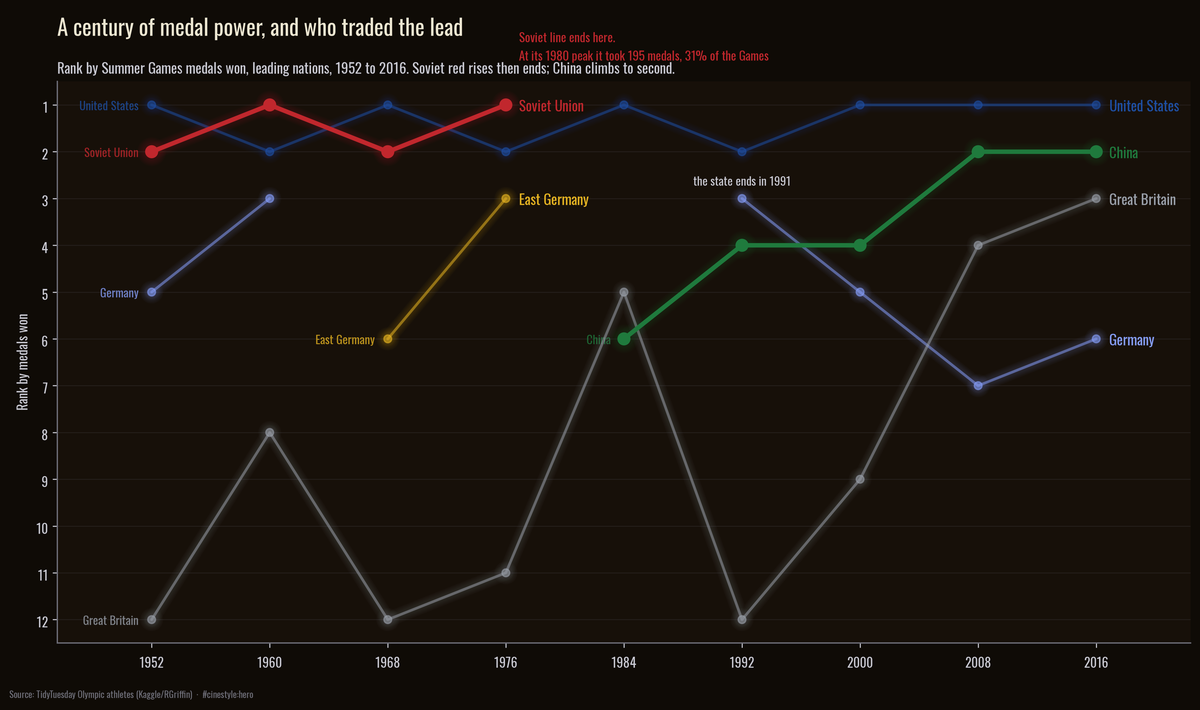
A Century of Medals
A century of Olympic medal power, and who traded the lead
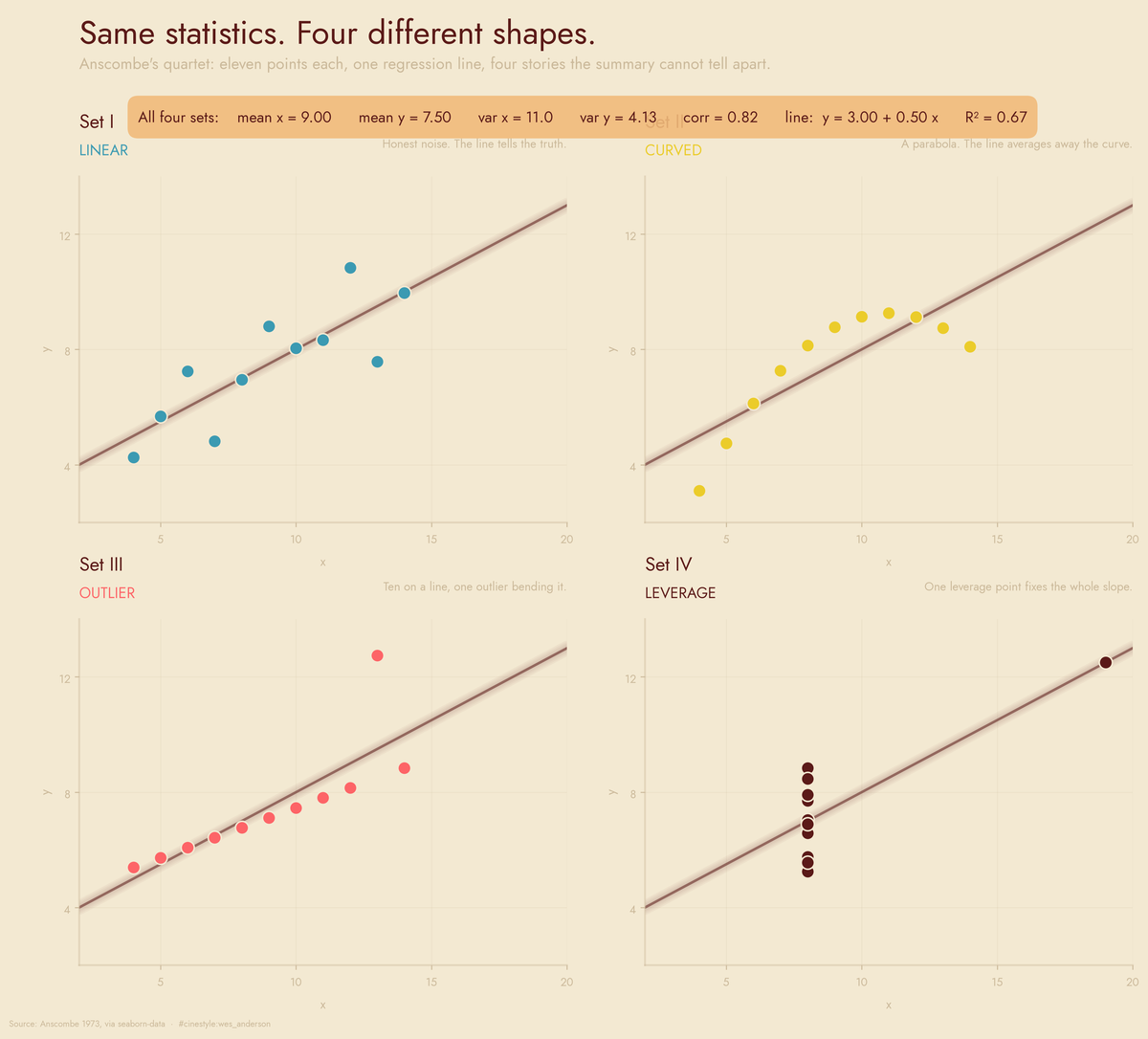
Anscombe's Quartet
Four datasets agree on every number and agree on nothing else
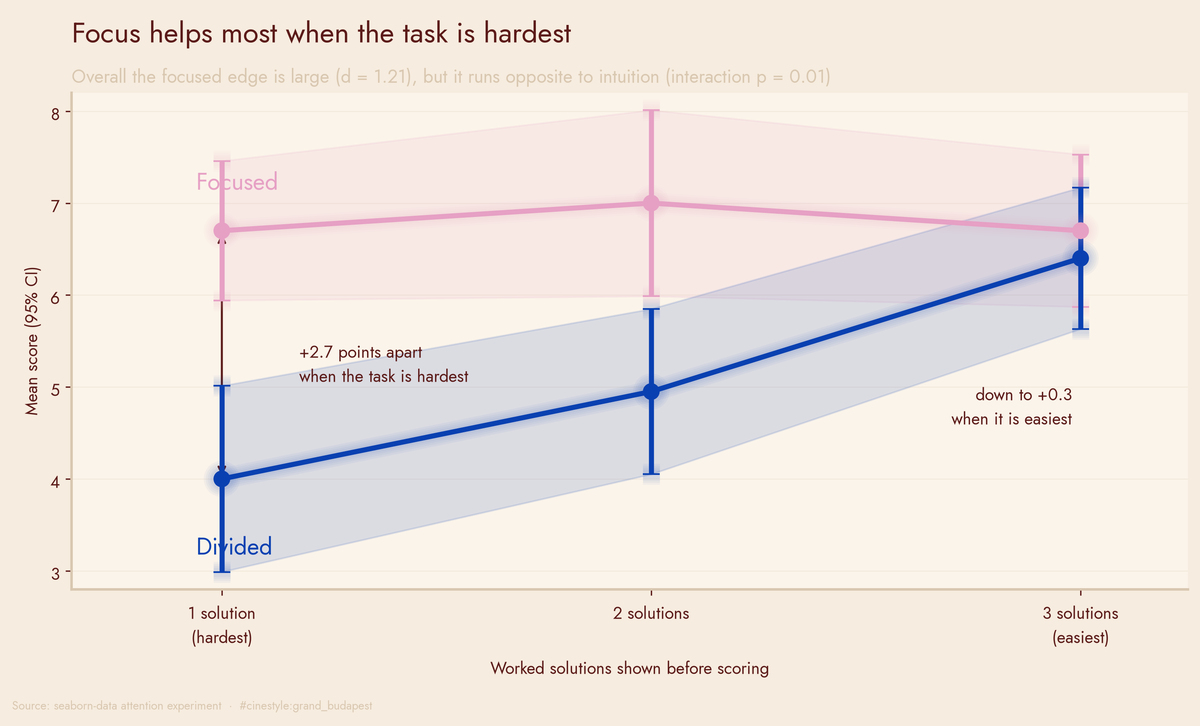
Attention and Performance
Focused attention wins by 1.68 points, until the task gets easier
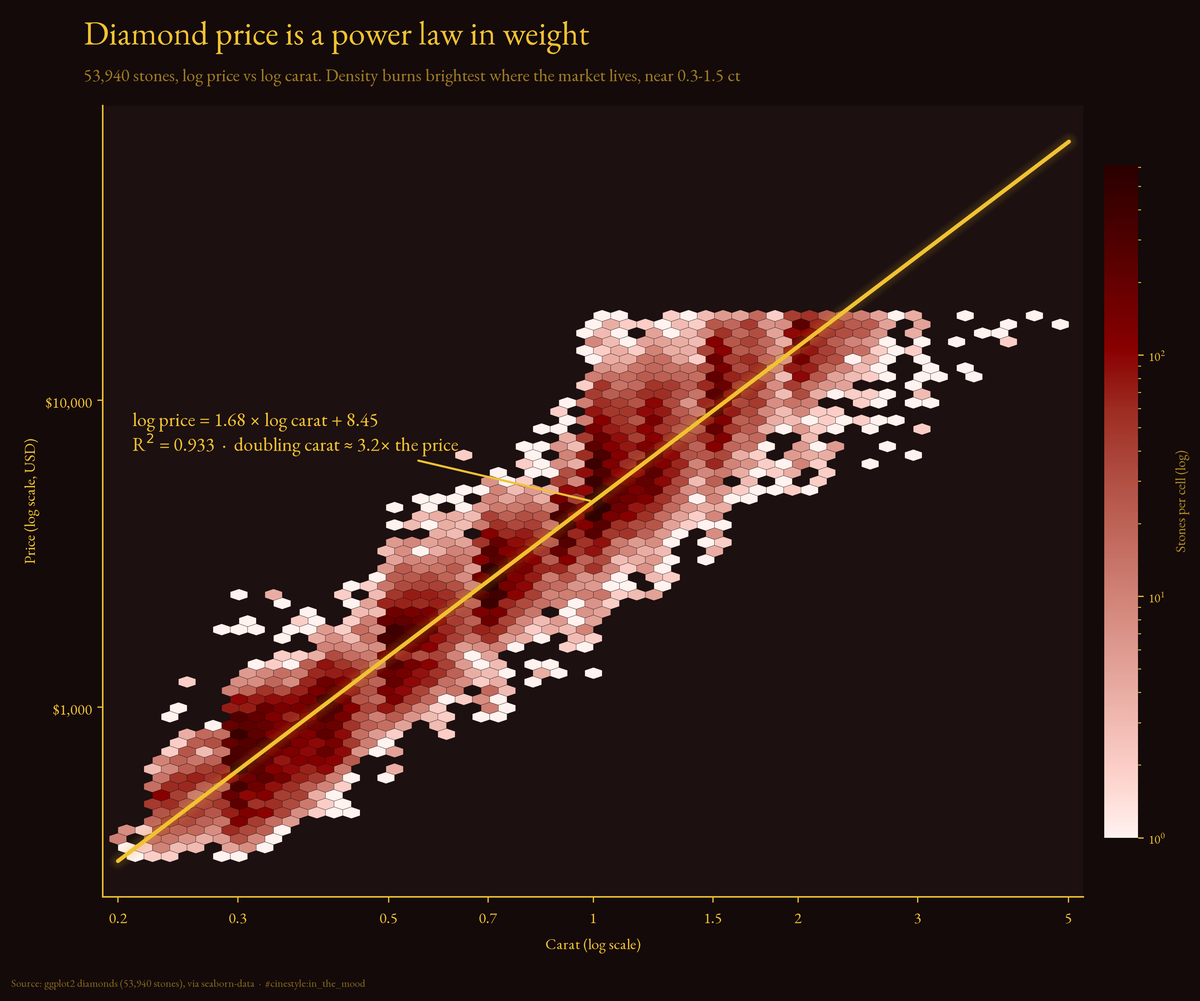
Reading Diamond Prices
The best-cut diamonds are the cheapest, and other lies the data tells

A Diamond's Four Cs
Two of a diamond's measurements are basically decoration
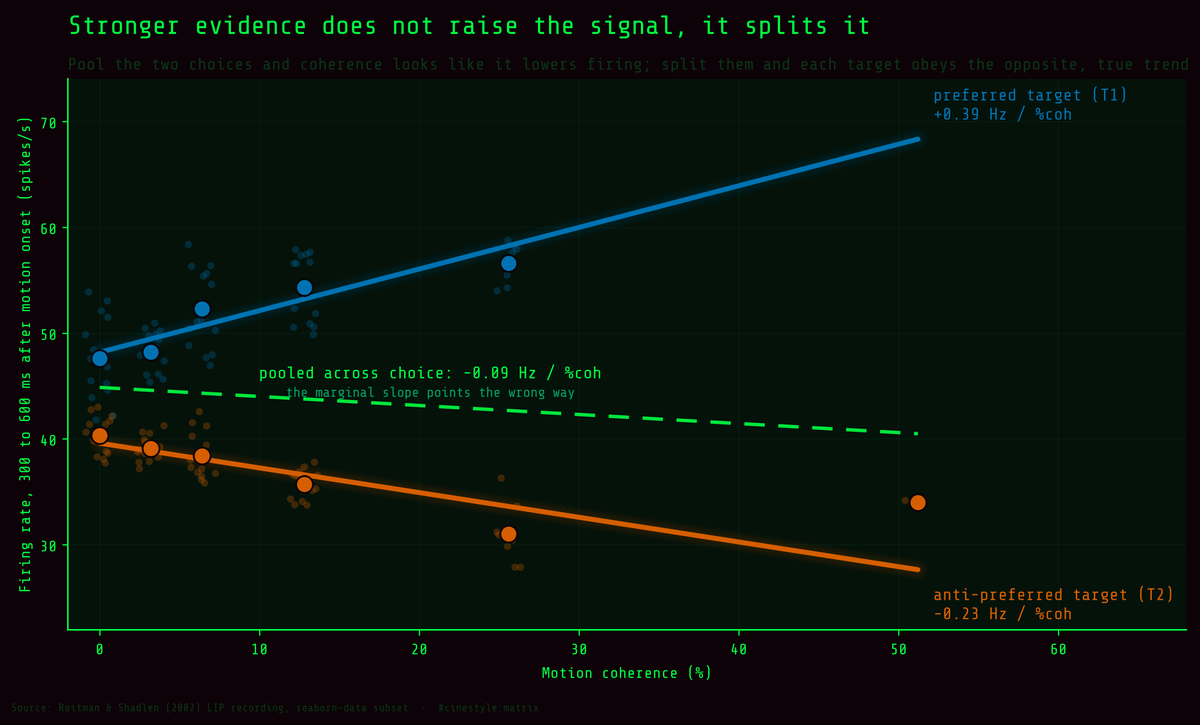
Evidence and Perception
Stronger evidence does not raise the signal, it splits it
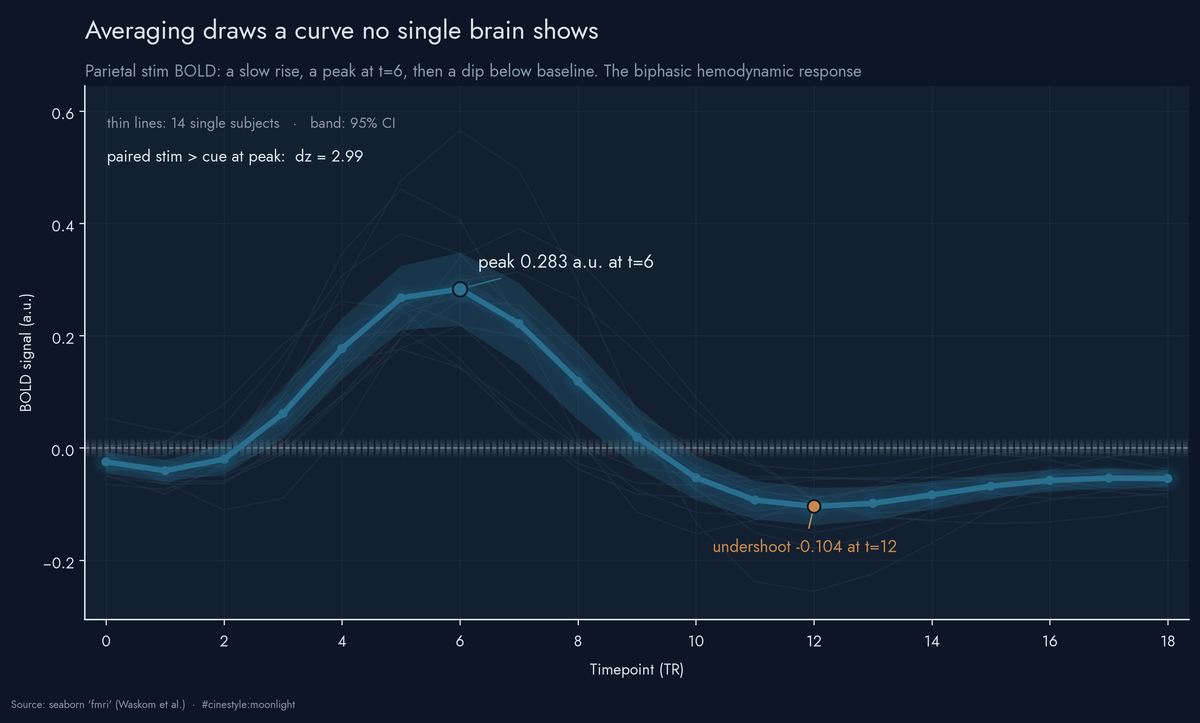
fMRI Response Curves
The average brain response is a curve, and averaging is what draws it
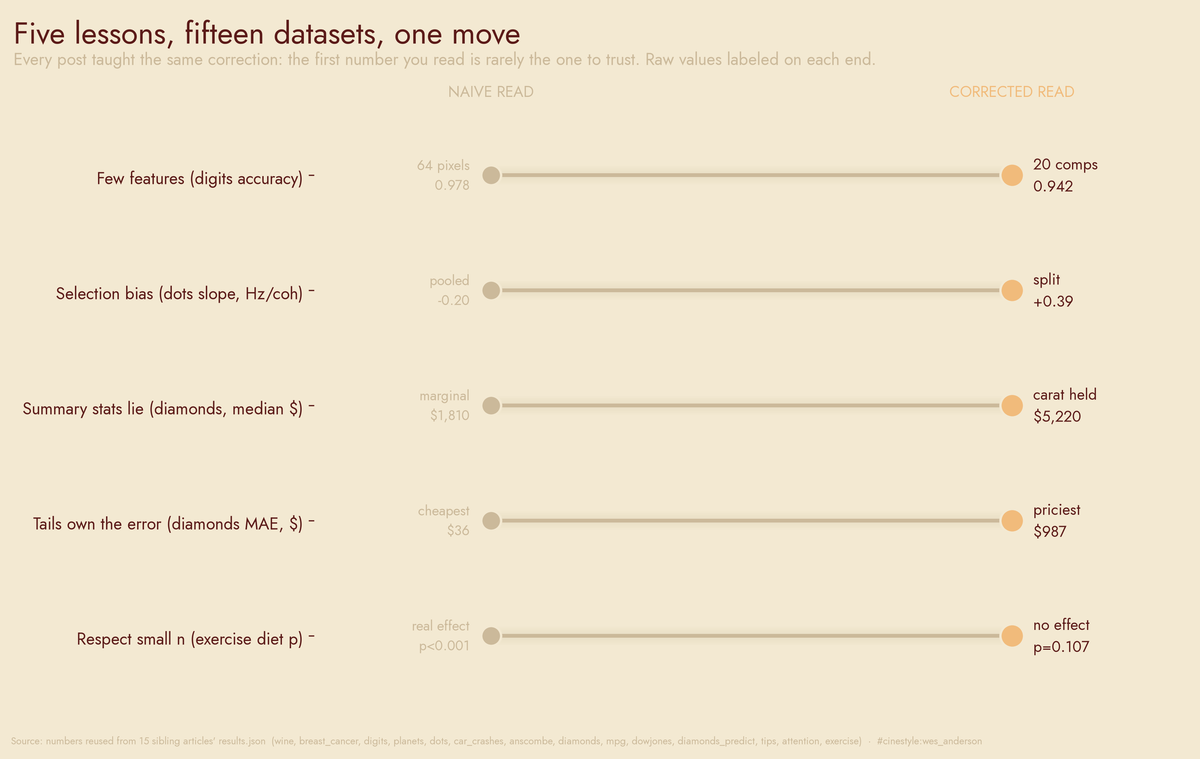
Lessons from 30 Datasets
Three numbers off a wine label, and four other things 30 datasets taught me
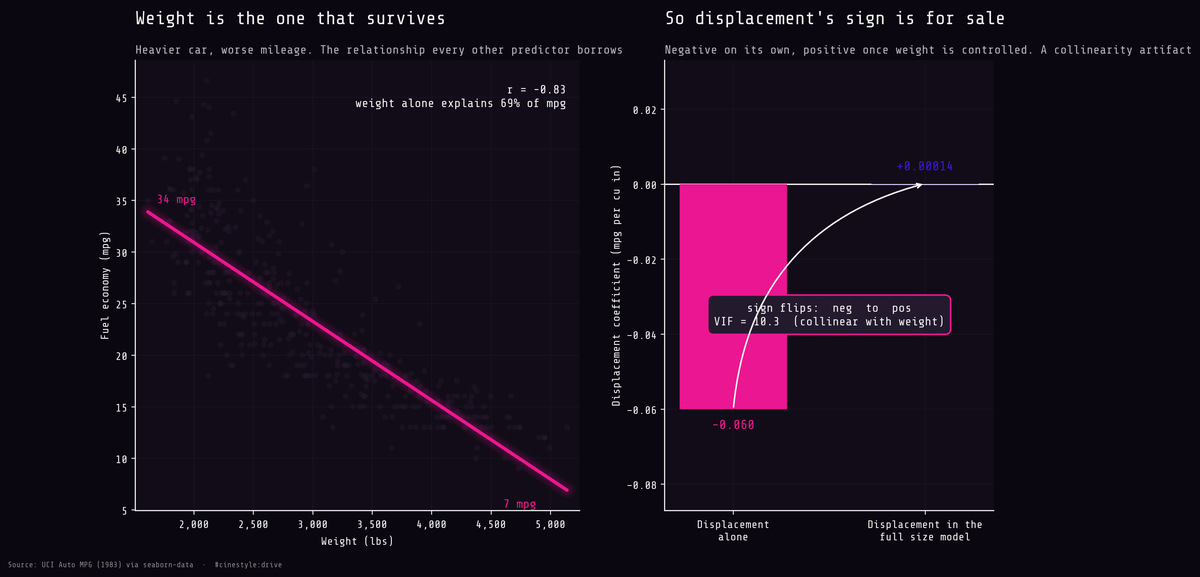
The MPG Paradox
A bigger engine made these cars more efficient, and other lies of regression
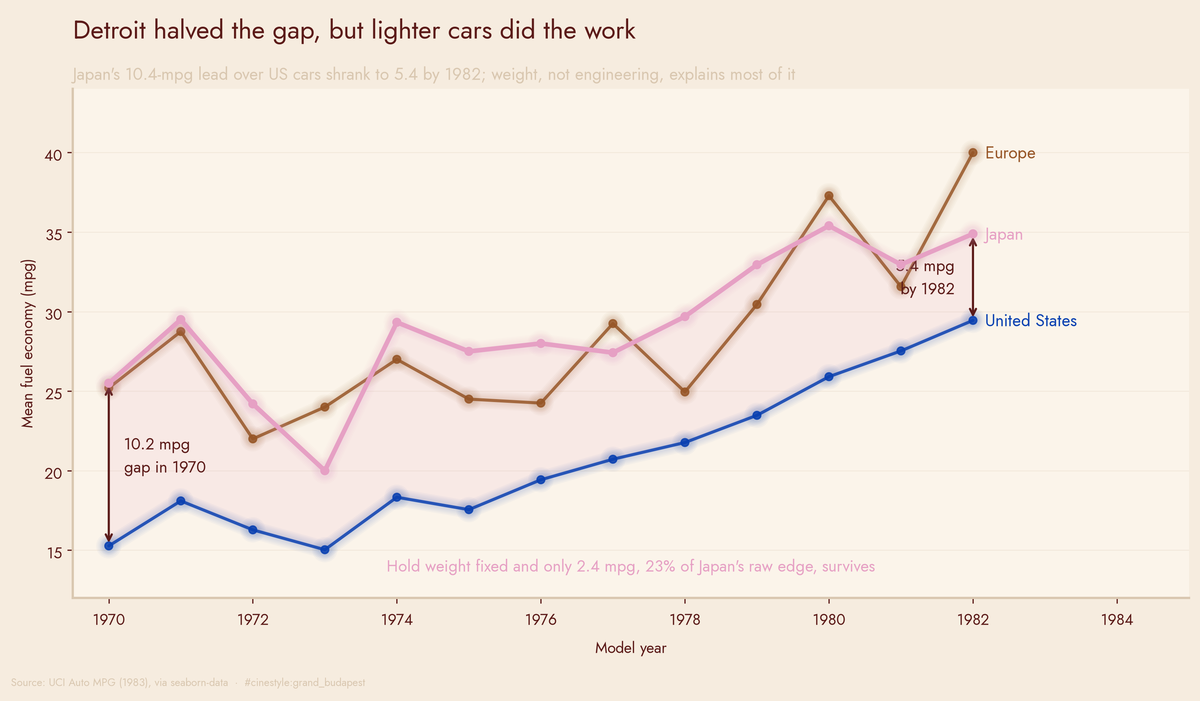
Detroit Versus Japan
Detroit caught up to Japan, but only after you weigh the cars
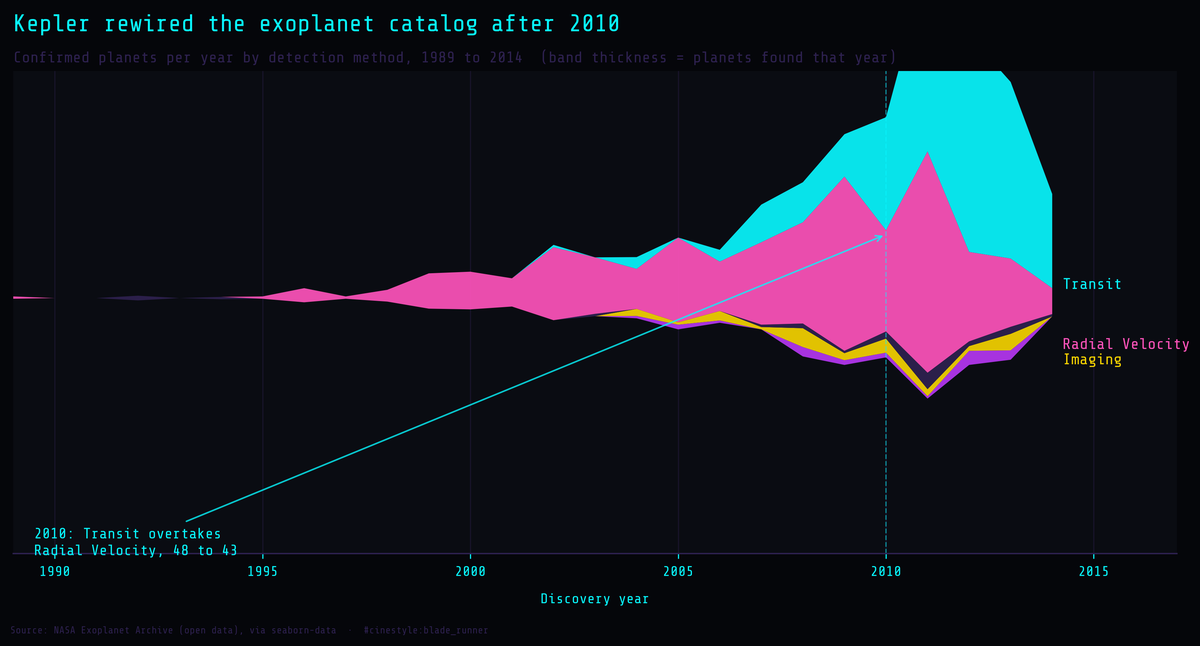
Mapping the Exoplanets
The exoplanet catalog is a map of our telescopes, not the galaxy
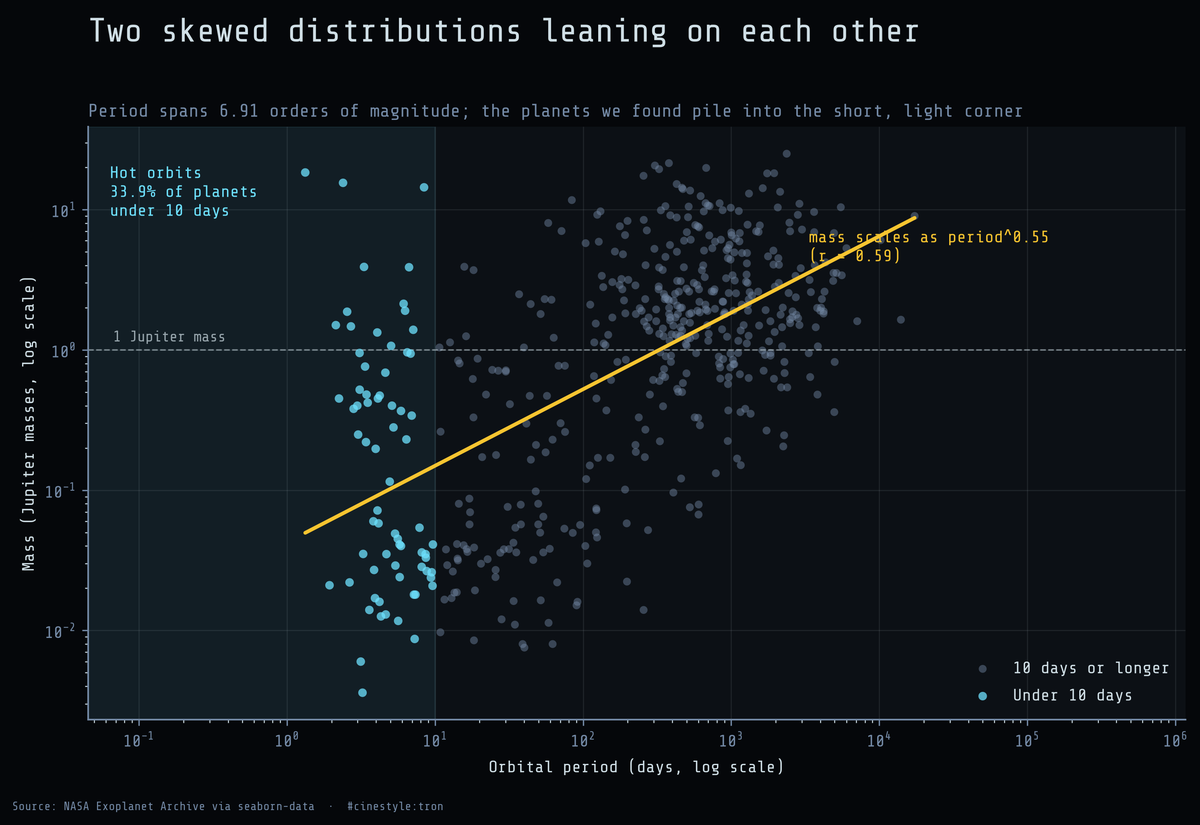
How Exoplanets Cluster
Almost seven orders of magnitude, and the planets pile up at one end

Seattle's Weather
Seattle rains 43.9% of the time. So does it sun.
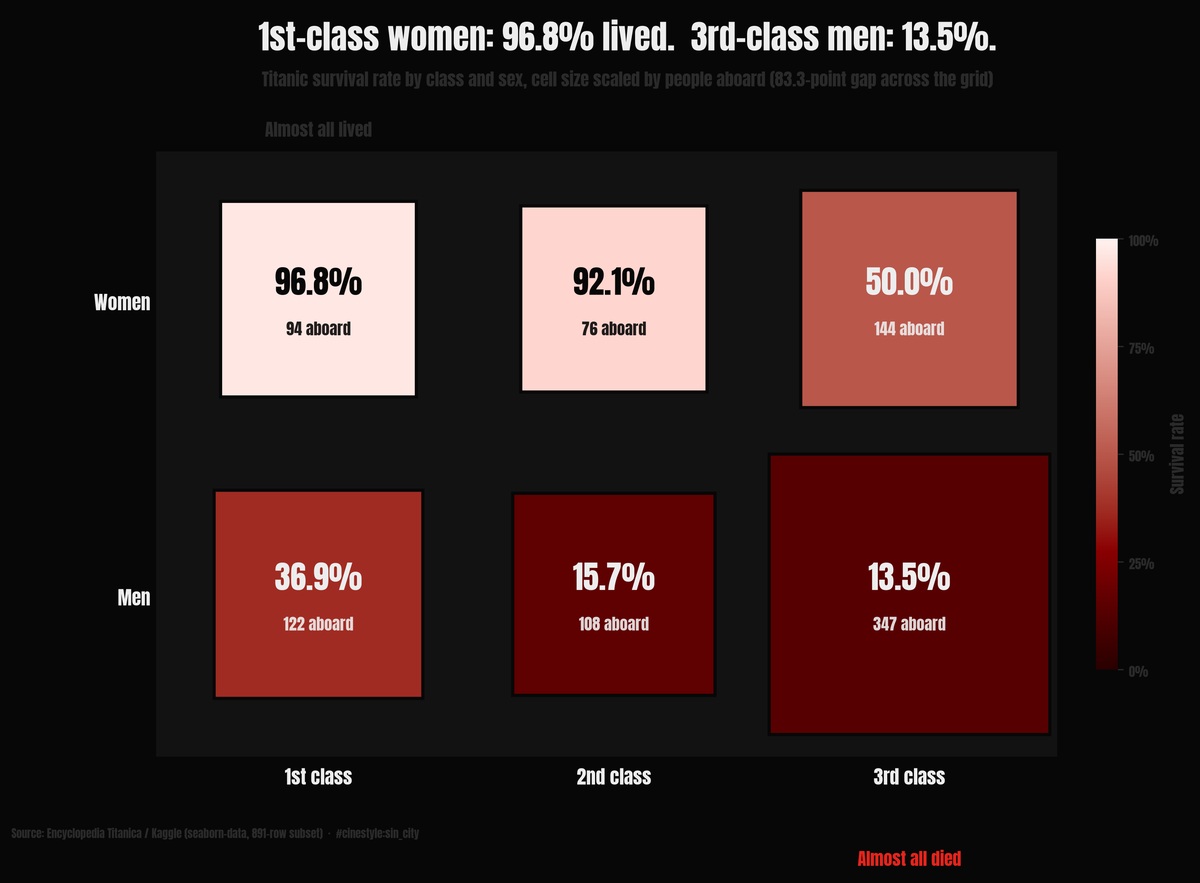
Who Survived the Titanic
Women and children first, or first class first?
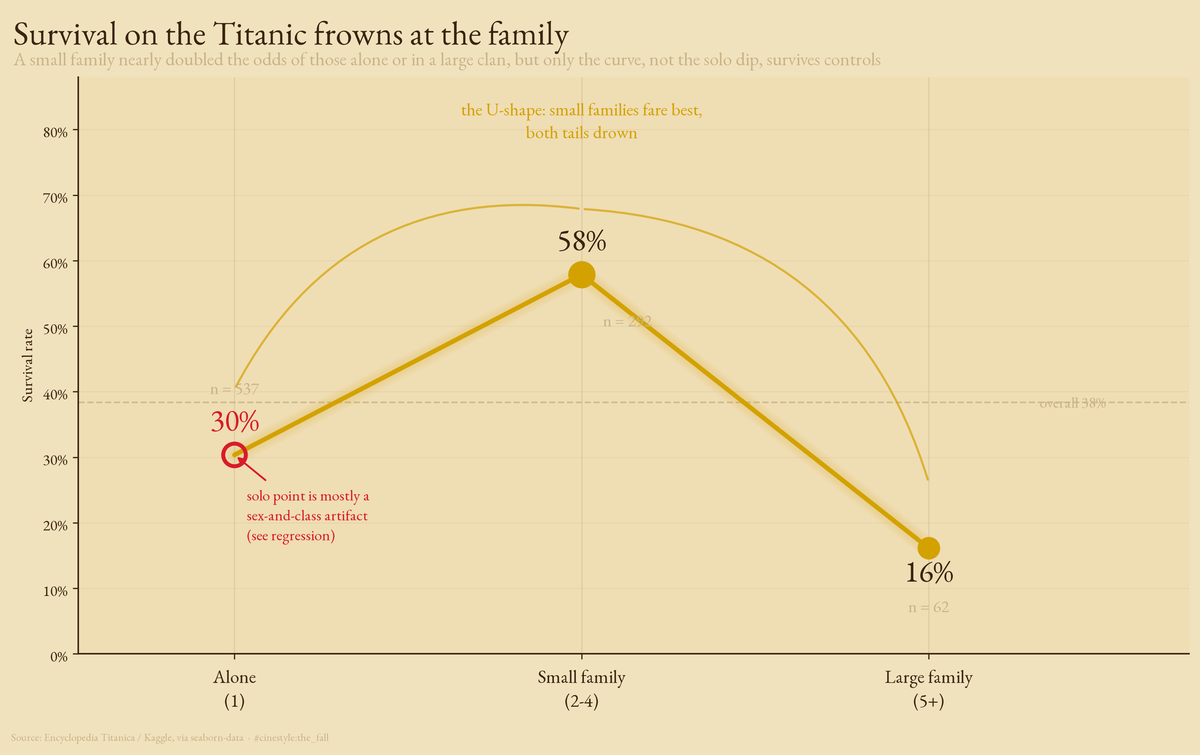
Titanic Families
The Titanic's loneliest passengers, and its largest families, drowned together
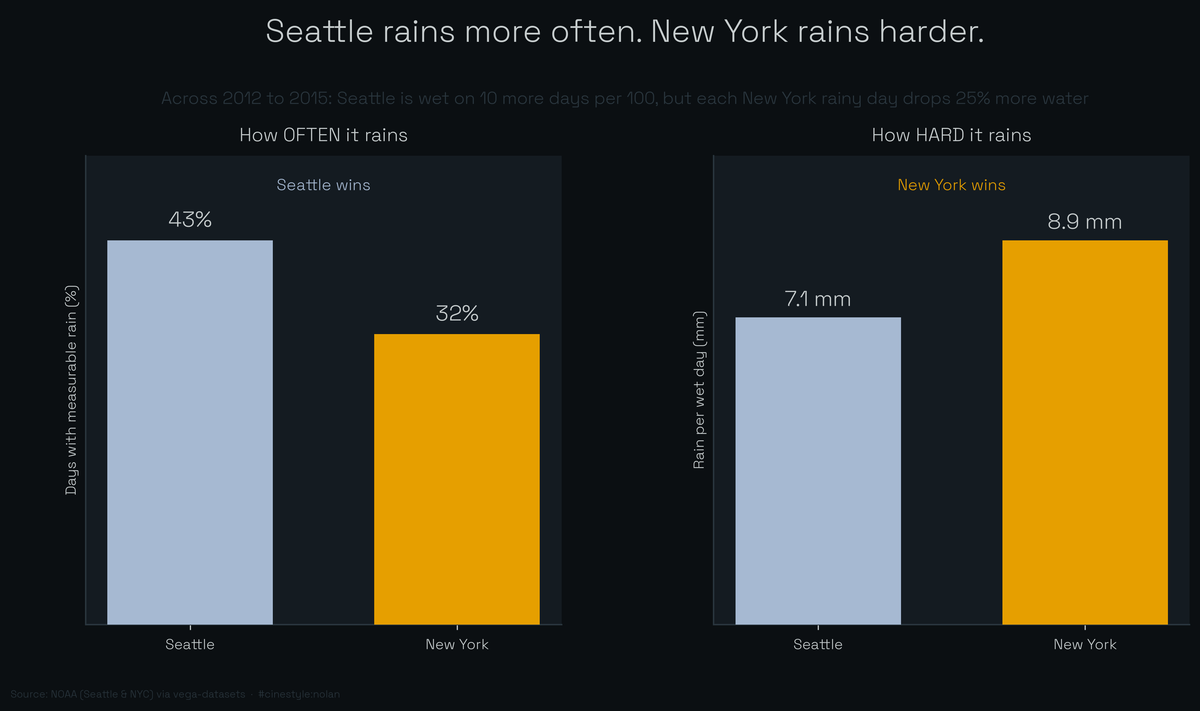
Seattle Versus New York
Seattle rains on more days than New York, and still ends up drier
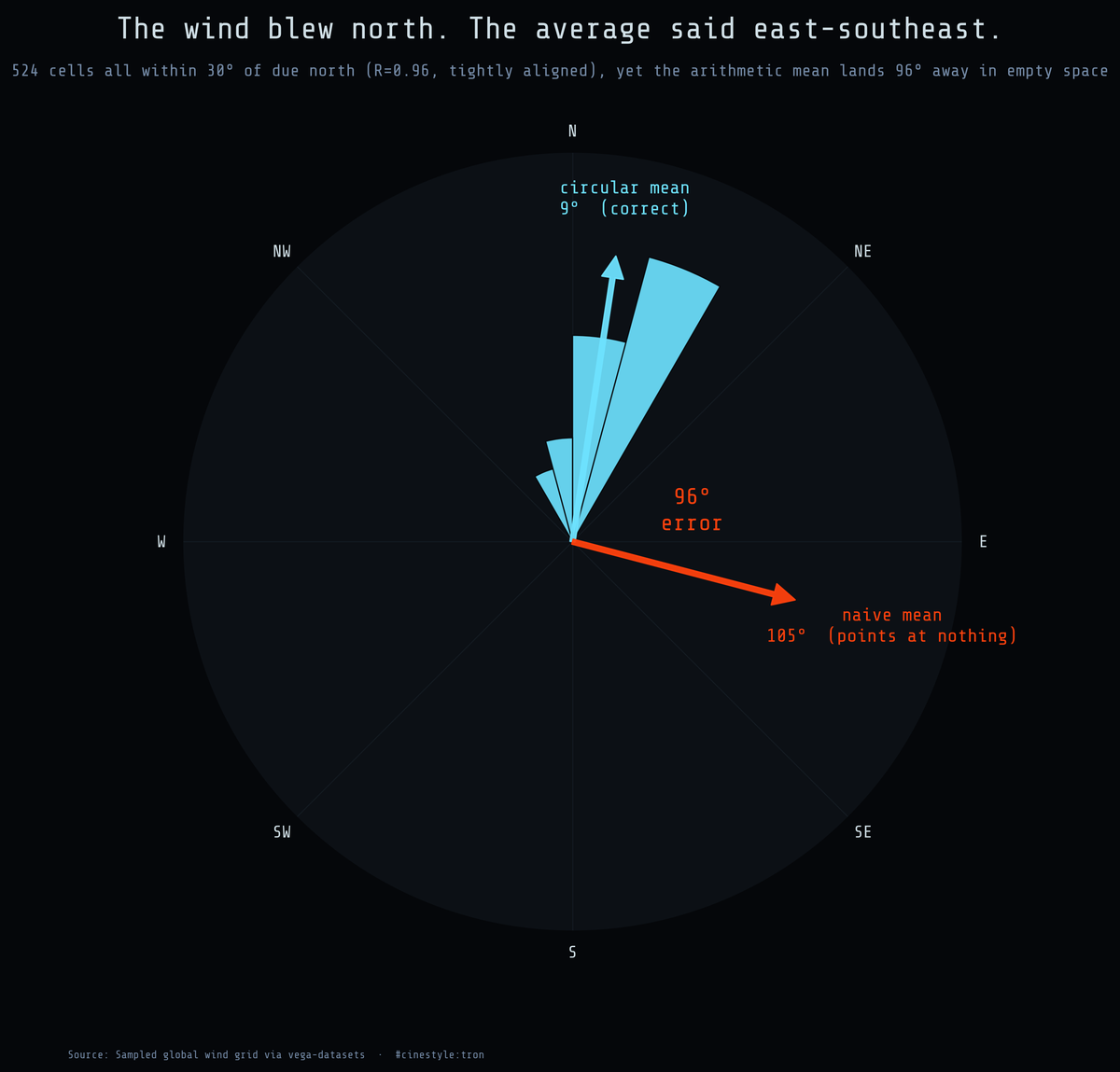
Averaging the Wind
The wind blew north. The average said east-southeast.
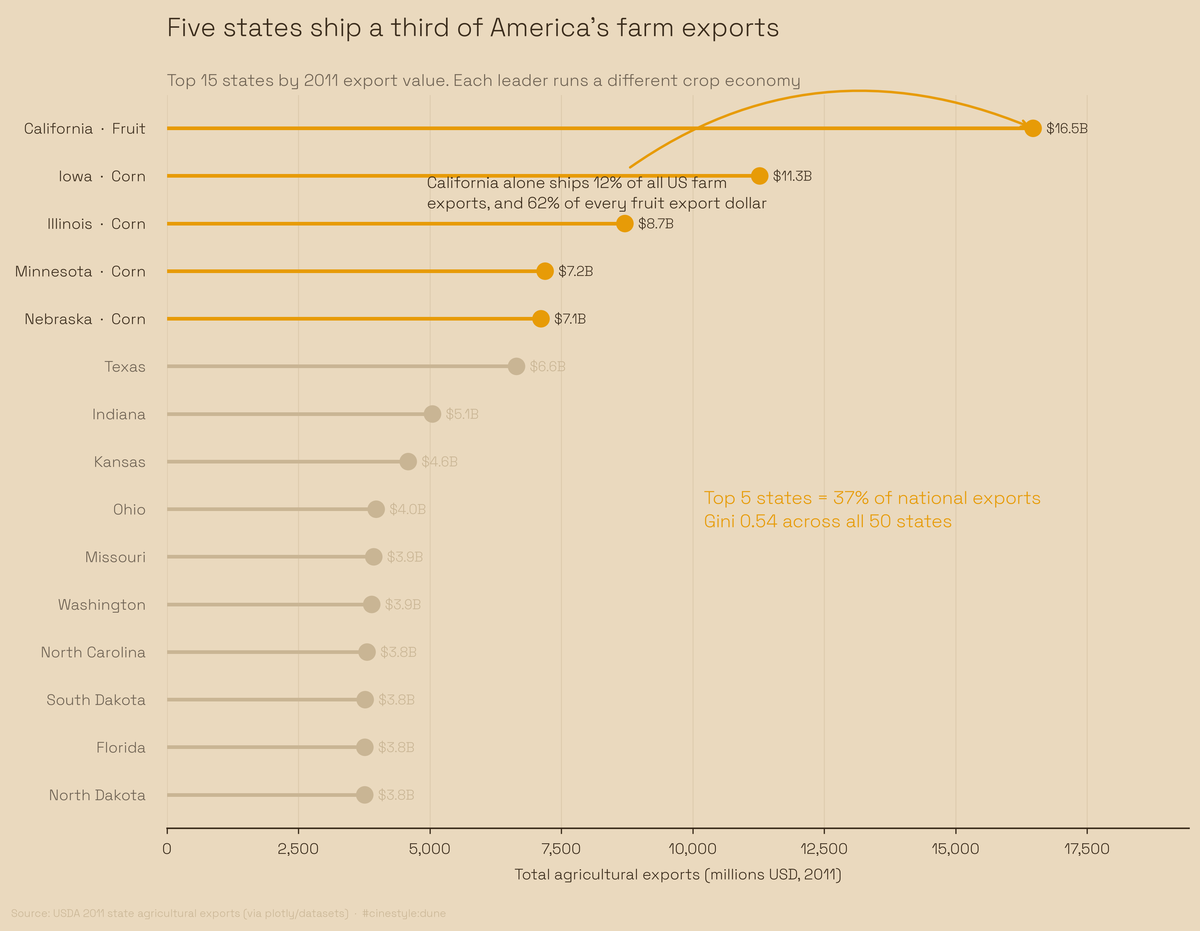
America's Farm Exports
Five states ship a third of US farm exports, and none grow the same thing
Cinestyle: matplotlib themes pulled from film
A small Python library of matplotlib themes — Film Noir, Ghibli, Wes Anderson, Blade Runner, Star Wars — applied to 50,000 IMDB reviews.
WebAssembly visualization with Rust: when JavaScript runs out of room
Building browser-side data visualizations in Rust compiled to WebAssembly — particle systems, large-dataset rendering, and the practical wins over a pure-JS implementation.
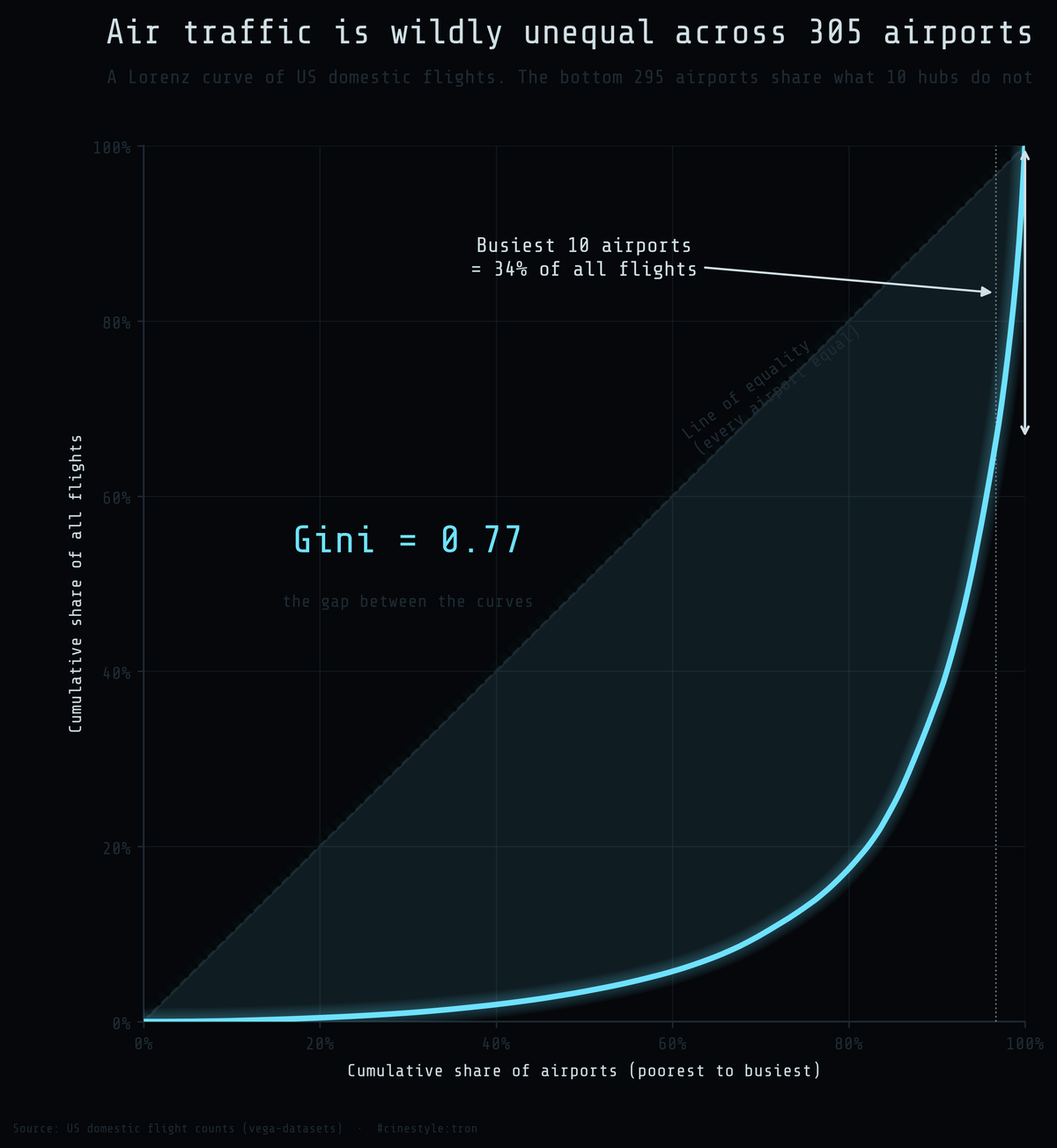

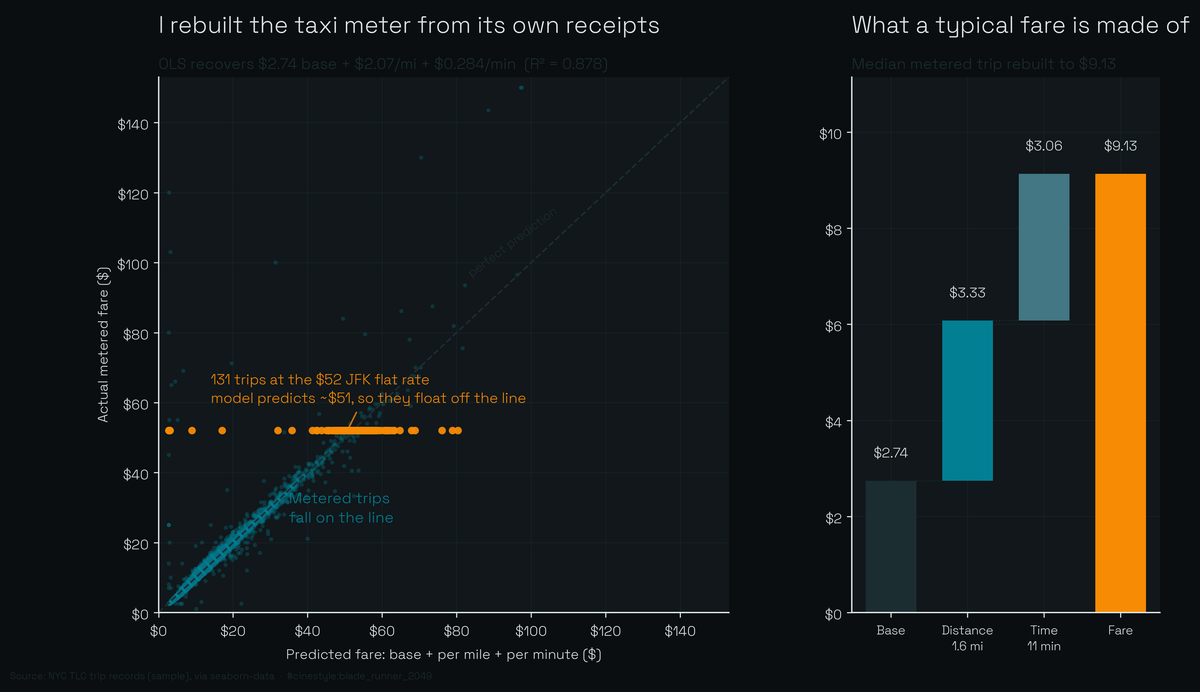
Database optimization: a working reference
Six database optimization techniques — predicate pushdown, row group pruning, result caching, async I/O, indexes, and where SIMD goes wrong — with impact numbers and code.
Replacing DuckDB with Rust: 10.4× through predicate pushdown
I replaced DuckDB with a custom Rust query engine for a trading-system time-series workload. Five iterations, 10.4× speedup, one optimization that backfired.
Database performance optimization: a reference (Part 1)
A working reference for production database tuning — SQLite PRAGMAs, schema, indexing, transactions, batching, pooling, and the monitoring that proves it's working.